{kind=link}
{kind=link}
Question Answering Sirah Nabawiyah for Multiple Choices

This is part of my thesis for completing my Master's studies in Informatics at ITB. The process of creating this dataset involved a previously shared dataset titled QASiNa-RC, which focuses on a reading comprehension dataset. The development of a reading comprehension task dataset resulting in QASiNa-RC is still insufficient to evaluate the performance of Generative-LLMs, especially in answering questions without context. Therefore, the creation of a new type of dataset supporting context-free questions in a multiple-choice format was carried out and named Question Answering Sirah Nabawiyah for Multiple Choices (QASiNa-MC).
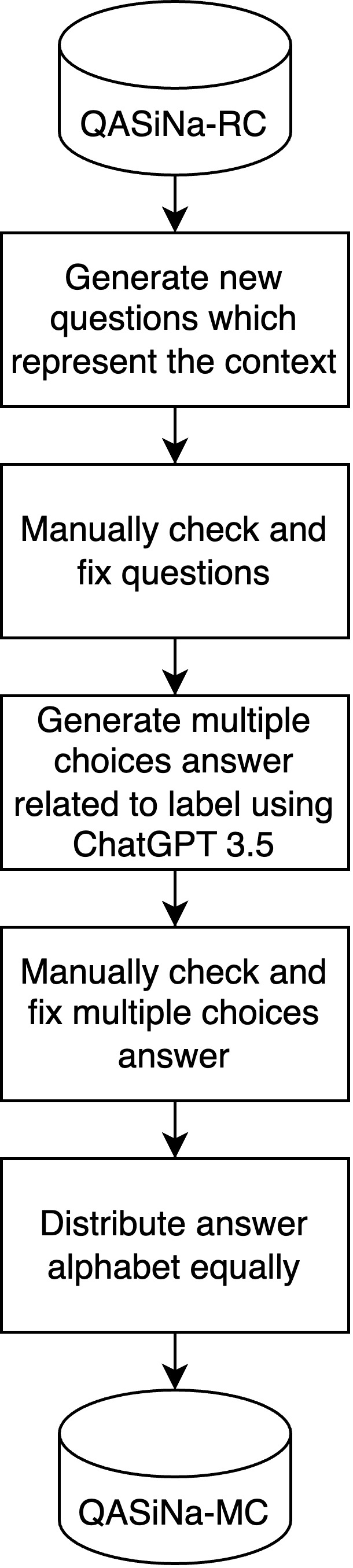
Creation of QASiNa-MC initiated after QASiNa-RC experiments. Questions in QASiNa-RC could only be answered if context was provided. Without context, these questions would lose the information or clues about the events being referred to. Therefore, it was necessary to adjust the existing questions to align with the objectives of QASiNa-MC. The process of adjusting questions to avoid losing event information was carried out with the assistance of Generative-LLM by combining information from the title, context, and questions into a new set of questions. The results generated using Generative-LLM were then manually reviewed and refined.
The next step was to create answer choices with the help of Generative-LLM. This process used the updated question information and the correct answer, and Generative-LLM was tasked with generating four incorrect answers that were not too semantically distant from the correct one. The process of reviewing and refining these answer choices was subsequently performed manually.
Following this, an even distribution of answer labels was implemented to eliminate bias in selecting the same alphabetical option. There were five answer options labeled A, B, C, D, and E, and the labels were evenly distributed, with each having 100 instances. The order of the options was randomized using a random function to avoid sequential patterns. The manual review and refinement process ensured that there were no changes to the question-answer pairs from the original QASiNa-RC data.
Below is block diagram how QASiNa-MC created.
Language: Indonesian
Dataset format for QASiNa-MC is CSV.
500 instances of context, question and answer pairs
- ID : Question ID (integer)
- cotext_id : Context ID (integer)
- context_title : Context title (string)
- context_length : Length of context (integer)
- context : Full text of context (string)
- question type : Type of question (string)
- question : Multiple choices question (string)
- A : Option A (string)
- B : Option B (string)
- C : Option C (string)
- D : Option D (string)
- E : Option E (string)
- answer : Answer label (A/B/C/D/E)
@MISC{Rizqullah2024,
author = {Rizqullah, Muhammad Razif and Purwarianti, Ayu and Aji, Alham Fikri},
title = {Religious Domain-Indonesian Sirah Nabawiyah Question Answering Using Generative-LLM},
year = {2024},
howpublished = {Master’s Program Thesis, Institut Teknologi Bandung},
keywords={QASiNa;reading comprehension;multiple choices;Masked-LM;Generative-LLM},
url = {https://digilib.itb.ac.id/gdl/view/80969}
}