This repository contains a comprehensive guide to various classification algorithms in machine learning. This guide covers both theoretical concepts and practical implementation examples. The algorithms discussed include Logistic Regression, K-Nearest Neighbors (KNN), Support Vector Machines (SVM), Naive Bayes, Decision Tree, and Random Forest classifiers.
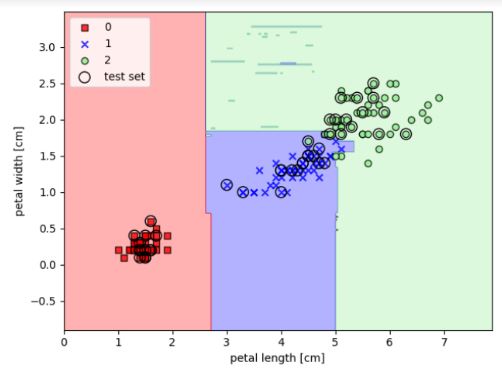
Classification is a type of supervised learning that predicts the class or category of a data point. It is best used when the output variable is discrete. This repository explores different classification algorithms and their implementation using Python.
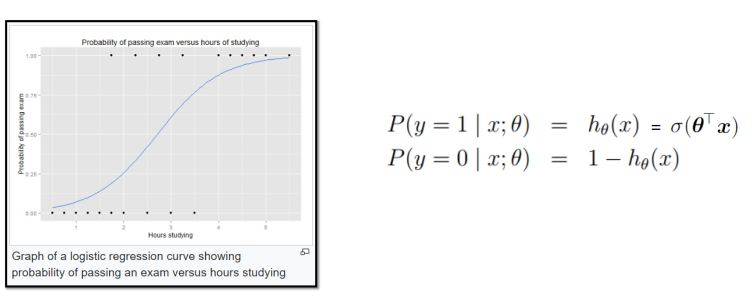
Logistic Regression is used for binary classification problems. It models the probability distribution of the output variable using a sigmoid function.
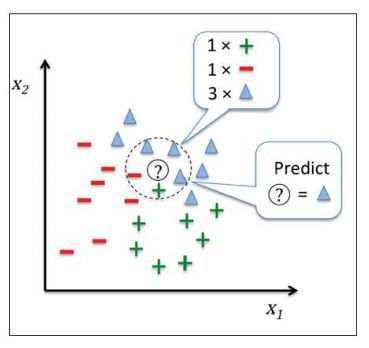
KNN is a simple, instance-based learning algorithm that assigns a data point to the class of its nearest neighbors.
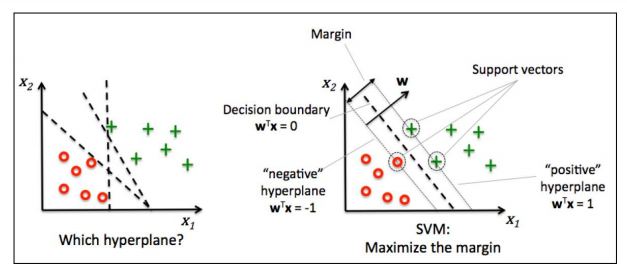
SVMs are powerful classifiers that find the hyperplane which best separates the classes. They can handle linear and non-linear data using kernel tricks.
Naive Bayes is a probabilistic classifier based on Bayes' Theorem. It assumes independence between features given the class label.

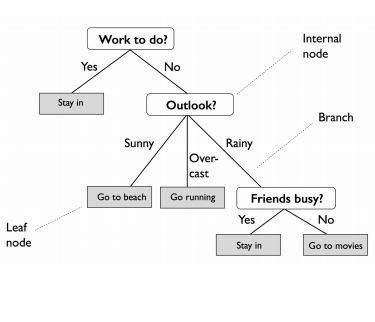
Decision Trees classify data by splitting it into subsets based on feature values, creating a tree of decisions.
Random Forests are ensembles of Decision Trees, which improve classification accuracy by reducing overfitting.
- Spam Detection: Classifying emails as spam or ham.
- Customer Segmentation: Identifying different customer segments based on purchase behavior.
- Loan Approval: Predicting if a bank loan should be granted.
- Sentiment Analysis: Classifying social media posts as positive or negative.
Clone the repository and install the necessary dependencies.
git clone https://github.com/your-username/ml-classification-algorithms.git
cd ml-classification-algorithms
pip install -r requirements.txtExamples of using each classifier can be found in the examples directory. Each example includes data loading, model training, and prediction.
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from logistic_regression import LogisticRegressionModel
# Load dataset
X, y = load_data('dataset.csv')
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize and train model
model = LogisticRegressionModel()
model.train(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate model
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')Contributions are welcome! Please read the contributing guidelines before submitting a pull request.
This project is licensed under the MIT License. See the LICENSE file for details.
For detailed tutorials and theoretical explanations, please refer to the included markdown files and Jupyter notebooks. If you have any questions or need further clarification, feel free to open an issue or contact the repository maintainers.