Feature stores are central data stores to power operational machine learning models. They help you store transformed feature values in a scalable and performant database. Real-time inference requires features to be returned to applications with low latency at scale. This is where ScyllaDB can play a crucial role in your machine learning infrastructure.
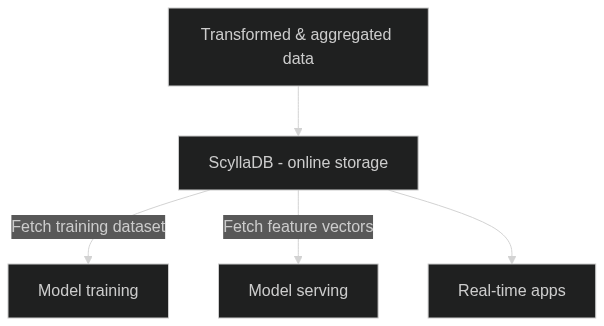
ScyllaDB is a real-time high-throughput NoSQL database that is best suited for feature stores where you require low latency consistently, and need peta-byte scalability.
- Low-latency: ScyllaDB can provide <10 ms P99 latency. Low latency can speed up training time and leads to faster model development.
- High-throughput: Training requires huge amounts of data and processing large datasets with many millions of operations per second - something that ScyllaDB excels at.
- Large-scale: ScyllaDB can handle petabytes of data while still providing great performance.
Read how Medium is using ScyllaDB as a feature store.
This example project demonstrates a machine learning feature store use case for ScyllaDB.
You'll set up a database with flight feature data and use ScyllaDB to analyze flight delays.
git clone https://github.com/scylladb/scylladb-feature-store.gitTo complete this project, sign up for a free trial account on ScyllaDB Cloud. This is the easiest way to start using ScyllaDB.
If you prefer to use a self-hosted version of ScyllaDB, see installation options here (e.g. Docker).
Run the schema.cql file to create keyspace feature_store and table flight_features:
cqlsh "node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud" 9042 -u scylla -p "password" -f schema.cqlThis creates the following table in your database:
create table feature_store.flight_features(
FL_DATE TIMESTAMP,
OP_CARRIER TEXT,
OP_CARRIER_FL_NUM INT,
ORIGIN TEXT,
DEST TEXT,
CRS_DEP_TIME INT,
DEP_TIME FLOAT,
DEP_DELAY FLOAT,
TAXI_OUT FLOAT,
WHEELS_OFF FLOAT,
WHEELS_ON FLOAT,
TAXI_IN FLOAT,
CRS_ARR_TIME INT,
ARR_TIME FLOAT,
ARR_DELAY FLOAT,
CANCELLED FLOAT,
CANCELLATION_CODE TEXT,
DIVERTED FLOAT,
CRS_ELAPSED_TIME FLOAT,
ACTUAL_ELAPSED_TIME FLOAT,
AIR_TIME FLOAT,
DISTANCE FLOAT,
CARRIER_DELAY FLOAT,
WEATHER_DELAY FLOAT,
NAS_DELAY FLOAT,
SECURITY_DELAY FLOAT,
LATE_AIRCRAFT_DELAY FLOAT,
PRIMARY KEY (OP_CARRIER_FL_NUM)
);cqlsh "node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud" 9042 -u scylla -p "password"
scylla@cqlsh> COPY feature_store.flight_features FROM 'flight_features.csv';This will start ingesting data into your ScyllaDB instance:
op_carrier_fl_num|actual_elapsed_time|air_time|arr_delay|arr_time|cancellation_code|cancelled|carrier_delay|crs_arr_time|crs_dep_time|crs_elapsed_time|dep_delay|dep_time|dest|distance|diverted|fl_date |late_aircraft_delay|nas_delay|op_carrier|origin|security_delay|taxi_in|taxi_out|weather_delay|wheels_off|wheels_on|
-----------------+-------------------+--------+---------+--------+-----------------+---------+-------------+------------+------------+----------------+---------+--------+----+--------+--------+-------------------+-------------------+---------+----------+------+--------------+-------+--------+-------------+----------+---------+
4317| 96.0| 73.0| -19.0| 2113.0| | 0.0| | 2132| 2040| 112.0| -3.0| 2037.0|MLI | 373.0| 0.0|2018-12-31 02:00:00| | |OO |DTW | | 5.0| 18.0| | 2055.0| 2108.0|
3372| 94.0| 74.0| 81.0| 1500.0| | 0.0| 0.0| 1339| 1150| 109.0| 96.0| 1326.0|RNO | 564.0| 0.0|2018-12-31 02:00:00| 81.0| 0.0|OO |SEA | 0.0| 3.0| 17.0| 0.0| 1343.0| 1457.0|
1584| 385.0| 348.0| -21.0| 2023.0| | 0.0| | 2034| 1700| 394.0| -9.0| 1658.0|SFO | 2565.0| 0.0|2018-12-31 02:00:00| | |UA |EWR | | 13.0| 33.0| | 1731.0| 2019.0|
4830| 119.0| 85.0| -35.0| 1431.0| | 0.0| | 1437| 1245| 136.0| -13.0| 1232.0|MSP | 546.0| 0.0|2018-12-31 02:00:00| | |OO |MSP | | 16.0| 18.0| | 1250.0| 1415.0|
2731| 158.0| 146.0| -19.0| 1911.0| | 0.0| | 1930| 1800| 160.0| -8.0| 1800.0|MSP | 842.0| 0.0|2018-12-31 02:00:00| | |WN |PVD | | 7.0| 7.0| | 1807.0| 1904.0|
Now that you have some sample data to play with, let's see a decision tree example.
Create a new virtual environment and activate it:
virtualenv env
source env/bin/activateInstall requirements:
pip install scikit-learn pandas scylla-driverTo follow the code examples below you can either create a new python file or just use the Jupyter notebook that's in the repo. If you use the notebook make sure the edit the
config.pyfile with your credentials.
Connect to ScyllaDB:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier # Import Decision Tree Classifier
from sklearn.model_selection import train_test_split # Import train_test_split function
from sklearn import metrics #Import scikit-learn metrics module for accuracy calculation
from sqlalchemy import create_engine
from cassandra.cluster import Cluster, ExecutionProfile, EXEC_PROFILE_DEFAULT
from cassandra.policies import DCAwareRoundRobinPolicy, TokenAwarePolicy
from cassandra.auth import PlainTextAuthProvider
def pandas_factory(colnames, rows):
return pd.DataFrame(rows, columns=colnames)
def getCluster():
profile = ExecutionProfile(load_balancing_policy=TokenAwarePolicy(DCAwareRoundRobinPolicy(local_dc='AWS_US_EAST_1')),
row_factory=pandas_factory)
return Cluster(
execution_profiles={EXEC_PROFILE_DEFAULT: profile},
contact_points=[
""
],
port=9042,
auth_provider = PlainTextAuthProvider(username="scylla", password="******"))
cluster = getCluster()
session = cluster.connect()Query data into a dataframe:
query = "SELECT * FROM demo.flight_features;"
rows = session.execute(query)
df = rows._current_rowsSplit the dataset into features and target variable: Feature attributes:
actual_elapsed_timeair_timearr_timecrs_arr_timecrs_dep_timecrs_elapsed_timedep_timedistancetaxi_intaxi_outwheels_offwheels_onarr_delay
Target attribute:
dep_delay
#Features
feature_cols = ["actual_elapsed_time", "air_time",
"arr_time", "crs_arr_time", "crs_dep_time",
"crs_elapsed_time", "dep_time", "distance", "taxi_in", "taxi_out",
"wheels_off", "wheels_on", "arr_delay"]
X = df[feature_cols]
y = df.dep_delay # Target variable
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # 70% training and 30% testCreate the classifier:
# Create Decision Tree classifer object
clf = DecisionTreeClassifier()
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.052884615384615384Decision tree visualization in text form
from sklearn.tree import export_text
tree_rules = export_text(clf, feature_names=feature_cols)
print(tree_rules)| | | | |--- taxi_in > 5.50
| | | | | |--- crs_arr_time <= 1307.50
| | | | | | |--- crs_dep_time <= 514.00
| | | | | | | |--- dep_time <= 501.00
| | | | | | | | |--- dep_time <= 272.50
| | | | | | | | | |--- class: 14.0
| | | | | | | | |--- dep_time > 272.50
| | | | | | | | | |--- class: -5.0
| | | | | | | |--- dep_time > 501.00
| | | | | | | | |--- class: -3.0
| | | | | | |--- crs_dep_time > 514.00
| | | | | | | |--- wheels_off <= 553.50
| | | | | | | | |--- crs_dep_time <= 536.50
| | | | | | | | | |--- wheels_on <= 745.50
| | | | | | | | | | |--- air_time <= 55.00
| | | | | | | | | | | |--- class: 6.0
| | | | | | | | | | |--- air_time > 55.00
| | | | | | | | | | | |--- truncated branch of depth 3
| | | | | | | | | |--- wheels_on > 745.50
| | | | | | | | | | |--- class: -2.0
| | | | | | | | |--- crs_dep_time > 536.50
| | | | | | | | | |--- class: -6.0
| | | | | | | |--- wheels_off > 553.50
| | | | | | | | |--- wheels_on <= 1257.00
| | | | | | | | | |--- taxi_out <= 12.50
| | | | | | | | | | |--- arr_delay <= -2.50
| | | | | | | | | | | |--- truncated branch of depth 5
| | | | | | | | | | |--- arr_delay > -2.50
| | | | | | | | | | | |--- truncated branch of depth 6
| | | | | | | | | |--- taxi_out > 12.50
| | | | | | | | | | |--- crs_elapsed_time <= 271.50
| | | | | | | | | | | |--- truncated branch of depth 11
| | | | | | | | | | |--- crs_elapsed_time > 271.50
| | | | | | | | | | | |--- truncated branch of depth 2
| | | | | | | | |--- wheels_on > 1257.00
| | | | | | | | | |--- class: 3.0
| | | | | |--- crs_arr_time > 1307.50
| | | | | | |--- crs_dep_time <= 1746.00
| | | | | | | |--- taxi_out <= 16.50
| | | | | | | | |--- crs_arr_time <= 1349.50
| | | | | | | | | |--- arr_delay <= -5.00
| | | | | | | | | | |--- class: 9.0
| | | | | | | | | |--- arr_delay > -5.00
| | | | | | | | | | |--- actual_elapsed_time <= 100.50
| | | | | | | | | | | |--- class: 10.0
| | | | | | | | | | |--- actual_elapsed_time > 100.50
| | | | | | | | | | | |--- truncated branch of depth 4
| | | | | | | | |--- crs_arr_time > 1349.50
| | | | | | | | | |--- wheels_on <= 1337.50
| | | | | | | | | | |--- class: -2.0
| | | | | | | | | |--- wheels_on > 1337.50
| | | | | | | | | | |--- taxi_in <= 15.50
| | | | | | | | | | | |--- truncated branch of depth 13
| | | | | | | | | | |--- taxi_in > 15.50
| | | | | | | | | | | |--- truncated branch of depth 6
| | | | | | | |--- taxi_out > 16.50
| | | | | | | | |--- crs_dep_time <= 1521.50
| | | | | | | | | |--- crs_dep_time <= 1105.00
| | | | | | | | | | |--- actual_elapsed_time <= 175.50
| | | | | | | | | | | |--- class: 5.0
| | | | | | | | | | |--- actual_elapsed_time > 175.50
| | | | | | | | | | | |--- truncated branch of depth 3
You can run and modify the classifier script using the Jupyter notebook file in the repository. Before running it locally, make sure to edit the config.py file with your proper (local or ScyllaDB Cloud) ScyllaDB configuration.
In the initial example, a table was created with each feature stored in its individual column. However, this approach becomes less efficient in practical scenarios, particularly when dealing with a large number of features. Adding numerous columns to the table becomes cumbersome and impractical.
Now let's implement a feature store that uses narrow table design. Instead of storing feature in individual columns, you'll store features in individual row.
create table feature_store.flight_features_narrow (
OP_CARRIER_FL_NUM INT,
FL_DATE TIMESTAMP,
FEATURE_NAME TEXT,
FEATURE_VALUE FLOAT,
PRIMARY KEY (OP_CARRIER_FL_NUM)
)This design allows you to easily add or remove features in the future without changing the schema.