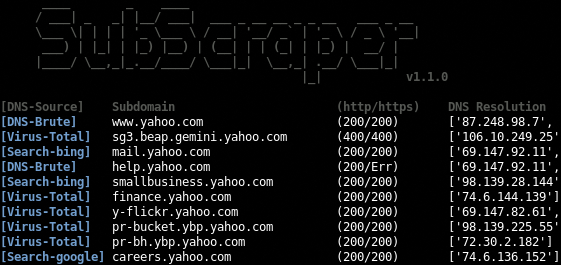
SubScraper uses DNS brute force, Google & Bing scraping, and Virus Total to enumerate subdomains. Written in Python3, SubScraper performs HTTP(S) requests and DNS "A" record lookups during the enumeration process to validate discovered subdomains. This provides further information to help prioritize targets and aid in potential next steps. Post-Enumeration, "CNAME" lookups are displayed to identify subdomain takeover opportunities.
Starting in SubScraper v1.2.0, users have the option of adding an API Key for Censys.io to perform subdomain enumeration using the SSL Cert database. Create an account to get a free API key here: https://censys.io/register.
git clone https://github.com/m8r0wn/subscraper
cd subscraper
pip3 install -r requirements.txtpython3 subscraper.py example.com
python3 subscraper.py -t 5 -o csv example.com -s Only use internet to find subdomains
-b Only use DNS brute forcing to find subdomains
-o OUTFILE Define output file type: csv/txt (Default: None)
-t MAX_THREADS Max threads (Default: 10)
-T TIMEOUT Timeout [seconds] for search threads (Default: 25)
-w SUBLIST Custom subdomain wordlist