forked from NanmiCoder/MediaCrawler
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
docs: update docs Create .gitattributes Update README.md
- Loading branch information
1 parent
bca6a27
commit e82dcae
Showing
20 changed files
with
1,548 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,3 @@ | ||
| *.js linguist-language=python | ||
| *.css linguist-language=python | ||
| *.html linguist-language=python |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,37 @@ | ||
| > **!!免责声明:!!** | ||
| > 本仓库的所有内容仅供学习和参考之用,禁止用于商业用途。任何人或组织不得将本仓库的内容用于非法用途或侵犯他人合法权益。本仓库所涉及的爬虫技术仅用于学习和研究,不得用于对其他平台进行大规模爬虫或其他非法行为。对于因使用本仓库内容而引起的任何法律责任,本仓库不承担任何责任。使用本仓库的内容即表示您同意本免责声明的所有条款和条件。 | ||
| # 仓库描述 | ||
| 这个代码仓库是一个利用[playwright](https://playwright.dev/)的爬虫程序 | ||
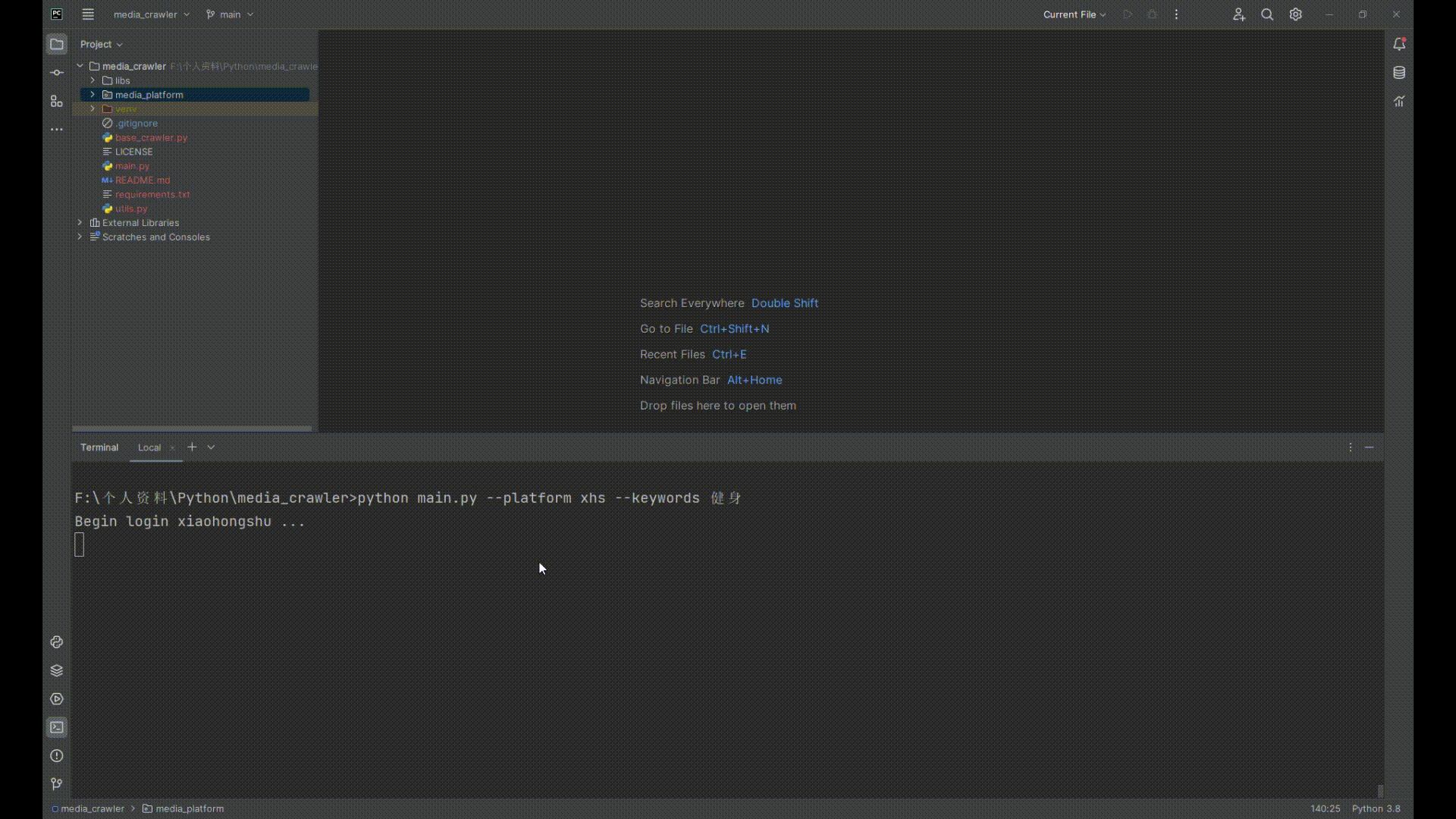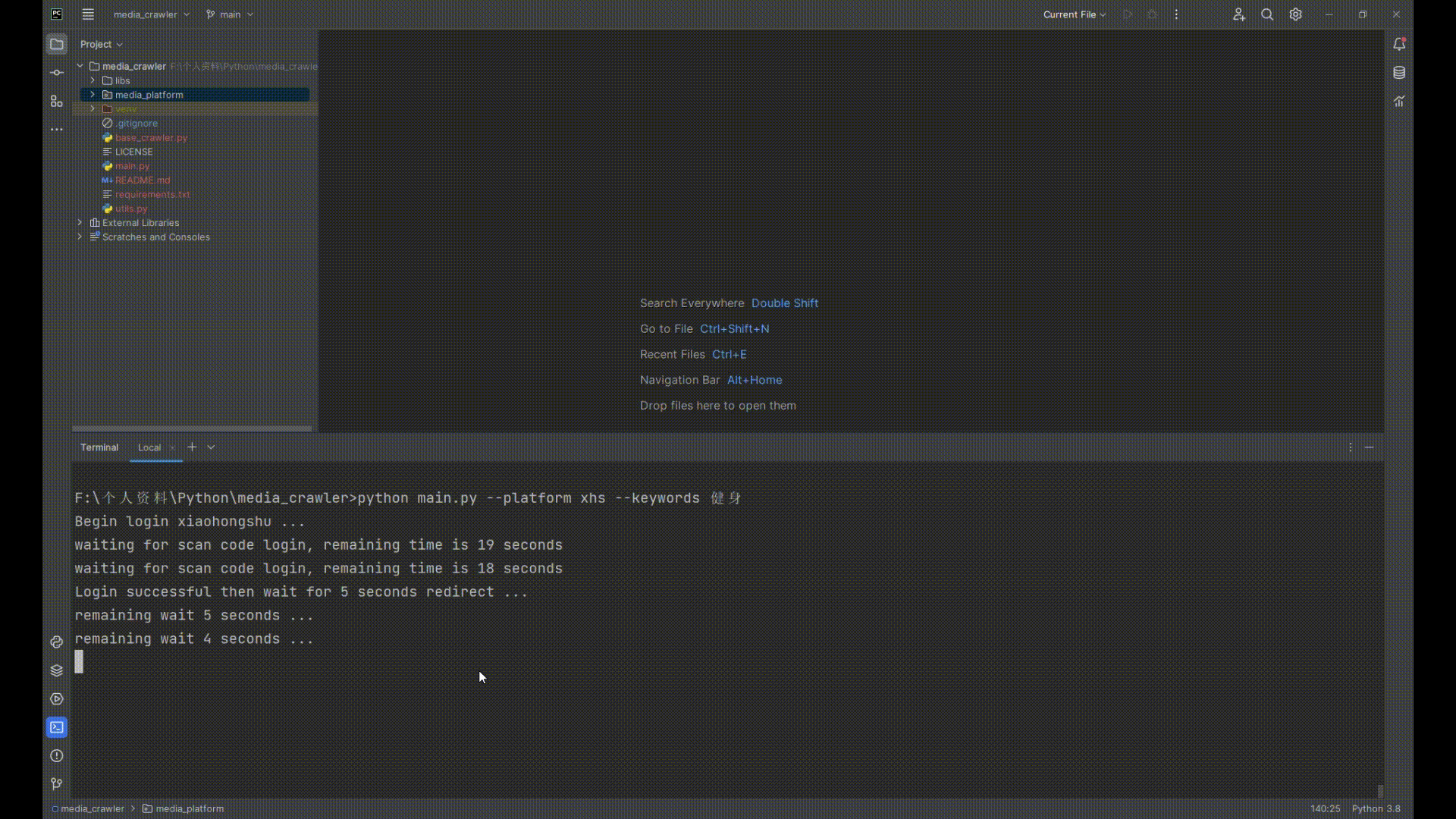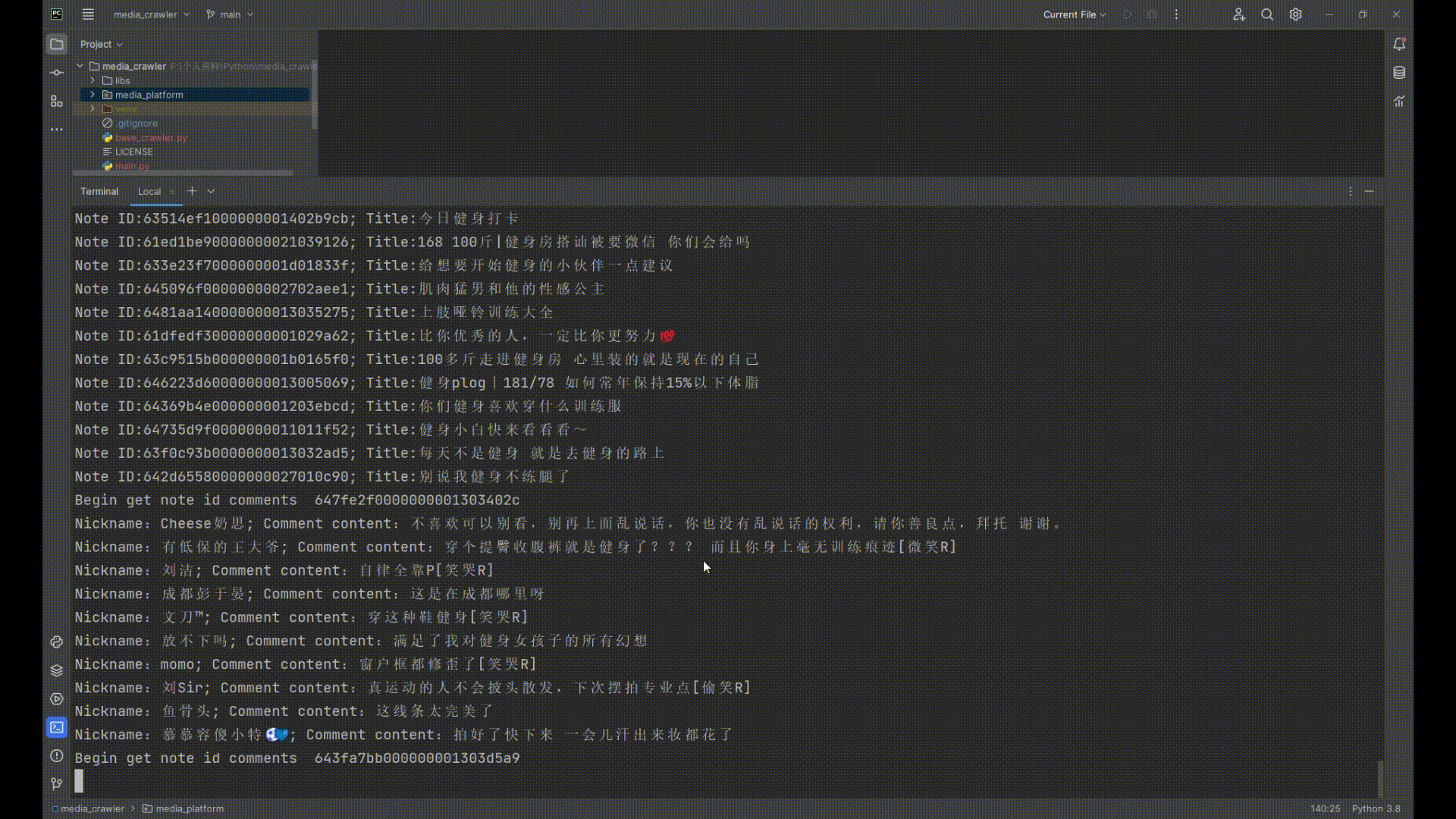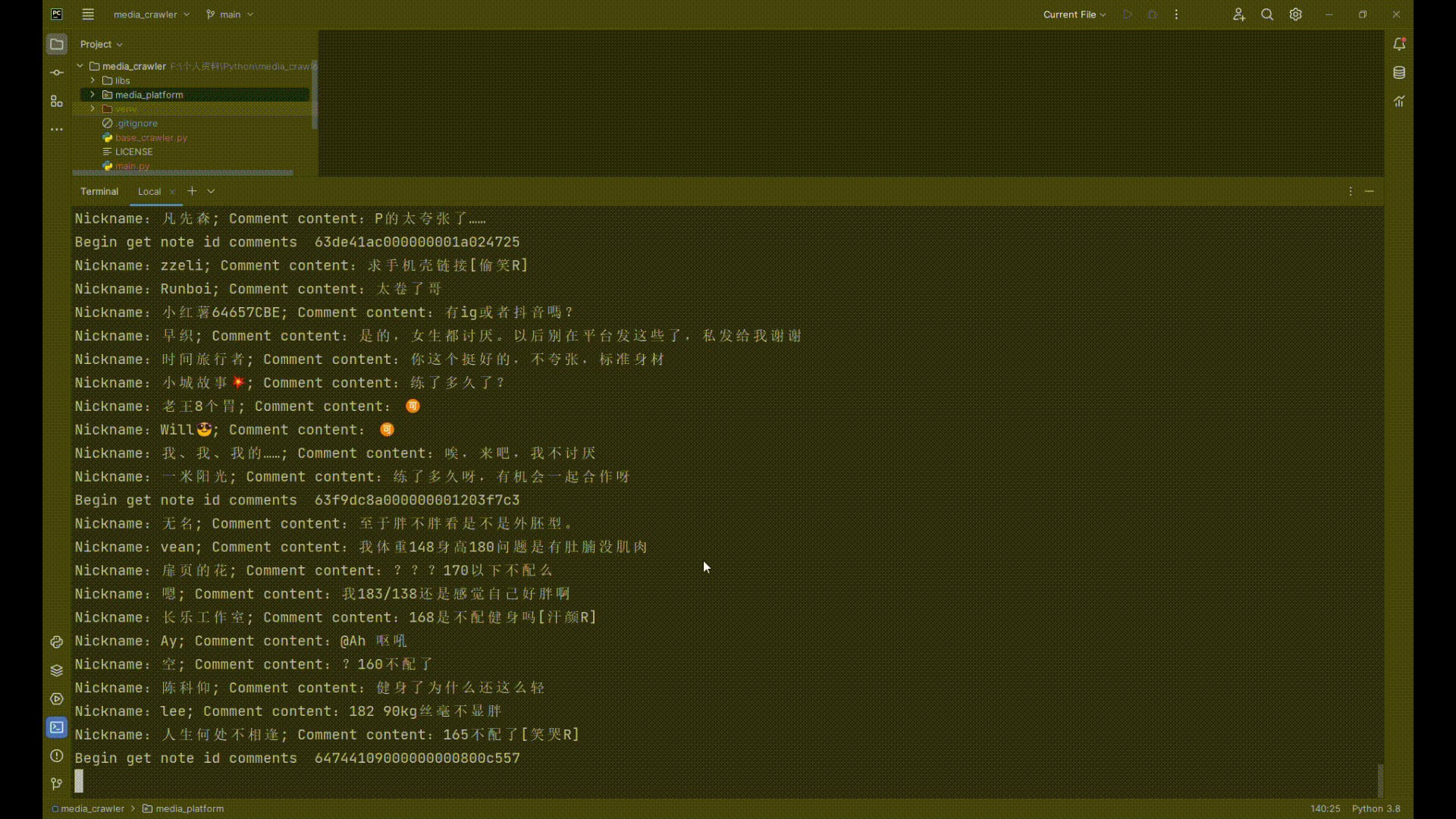
| 可以准确地爬取小红书、抖音的笔记、评论等信息,大概原理是:利用playwright登录成功后,保留登录成功后的上下文浏览器环境,通过上下文浏览器环境执行JS表达式获取一些加密参数,再使用python的httpx发起异步请求,相当于使用Playwright搭桥,免去了复现核心加密JS代码,逆向难度大大降低。 | ||
|
|
||
|
|
||
| ## 主要功能 | ||
|
|
||
| - [x] 爬取小红书笔记、评论 | ||
| - [ ] To do 爬取抖音视频、评论 | ||
|
|
||
| ## 技术栈 | ||
|
|
||
| - playwright | ||
| - httpx | ||
| - Web逆向 | ||
|
|
||
| ## 使用方法 | ||
|
|
||
| 1. 安装依赖库 | ||
| `pip install -r requirements.txt` | ||
| 2. 安装playwright浏览器驱动 | ||
| `playwright install` | ||
| 3. 运行爬虫程序 | ||
| `python main.py --platform xhs --keywords 健身` | ||
| 4. 打开小红书扫二维码登录 | ||
|
|
||
| ## 运行截图 | ||
|  | ||
|
|
||
| ## 参考 | ||
| 本仓库中小红书代码部分来自[ReaJason的xhs仓库](https://github.com/ReaJason/xhs),感谢ReaJason | ||
|
|
||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,23 @@ | ||
| from abc import ABC, abstractmethod | ||
|
|
||
|
|
||
| class Crawler(ABC): | ||
| @abstractmethod | ||
| def init_config(self, **kwargs): | ||
| pass | ||
|
|
||
| @abstractmethod | ||
| async def start(self): | ||
| pass | ||
|
|
||
| @abstractmethod | ||
| async def login(self): | ||
| pass | ||
|
|
||
| @abstractmethod | ||
| async def search_posts(self): | ||
| pass | ||
|
|
||
| @abstractmethod | ||
| async def get_comments(self, item_id: int): | ||
| pass |
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Large diffs are not rendered by default.
Oops, something went wrong.
Large diffs are not rendered by default.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,37 @@ | ||
| import sys | ||
| import asyncio | ||
| import argparse | ||
|
|
||
| from media_platform.douyin import DouYinCrawler | ||
| from media_platform.xhs import XiaoHongShuCrawler | ||
|
|
||
|
|
||
| class CrawlerFactory: | ||
| @staticmethod | ||
| def create_crawler(platform: str): | ||
| if platform == "xhs": | ||
| return XiaoHongShuCrawler() | ||
| elif platform == "dy": | ||
| return DouYinCrawler() | ||
| else: | ||
| raise ValueError("Invalid Media Platform Currently only supported xhs or douyin ...") | ||
|
|
||
|
|
||
| async def main(): | ||
| # define command line params ... | ||
| parser = argparse.ArgumentParser(description='Media crawler program.') | ||
| parser.add_argument('--platform', type=str, help='Media platform select (xhs|dy)...', default="xhs") | ||
| parser.add_argument('--keywords', type=str, help='Search note/page keywords...', default="健身") | ||
| args = parser.parse_args() | ||
| crawler = CrawlerFactory().create_crawler(platform=args.platform) | ||
| crawler.init_config( | ||
| keywords=args.keywords, | ||
| ) | ||
| await crawler.start() | ||
|
|
||
|
|
||
| if __name__ == '__main__': | ||
| try: | ||
| asyncio.run(main()) | ||
| except KeyboardInterrupt: | ||
| sys.exit() |
Empty file.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1 @@ | ||
| from .core import DouYinCrawler |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,42 @@ | ||
| from typing import Optional, Dict | ||
|
|
||
| import httpx | ||
| from playwright.async_api import Page | ||
|
|
||
|
|
||
| class DOUYINClient: | ||
| def __init__( | ||
| self, | ||
| timeout=10, | ||
| proxies=None, | ||
| headers: Optional[Dict] = None, | ||
| playwright_page: Page = None, | ||
| cookie_dict: Dict = None | ||
| ): | ||
| self.proxies = proxies | ||
| self.timeout = timeout | ||
| self.headers = headers | ||
| self._host = "https://www.douyin.com" | ||
| self.playwright_page = playwright_page | ||
| self.cookie_dict = cookie_dict | ||
|
|
||
| async def _pre_params(self, url: str, data=None): | ||
| pass | ||
|
|
||
| async def request(self, method, url, **kwargs): | ||
| async with httpx.AsyncClient(proxies=self.proxies) as client: | ||
| response = await client.request( | ||
| method, url, timeout=self.timeout, | ||
| **kwargs | ||
| ) | ||
| data = response.json() | ||
| if data["success"]: | ||
| return data.get("data", data.get("success")) | ||
| else: | ||
| pass | ||
|
|
||
| async def get(self, uri: str, params=None): | ||
| pass | ||
|
|
||
| async def post(self, uri: str, data: dict): | ||
| pass |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,61 @@ | ||
| import sys | ||
| import asyncio | ||
| from typing import Optional, List, Dict | ||
|
|
||
| from playwright.async_api import async_playwright | ||
| from playwright.async_api import Page | ||
| from playwright.async_api import Cookie | ||
| from playwright.async_api import BrowserContext | ||
|
|
||
| import utils | ||
| from .client import DOUYINClient | ||
| from base_crawler import Crawler | ||
|
|
||
|
|
||
| class DouYinCrawler(Crawler): | ||
| def __init__(self): | ||
| self.keywords: Optional[str] = None | ||
| self.scan_qrcode_time: Optional[int] = None | ||
| self.cookies: Optional[List[Cookie]] = None | ||
| self.browser_context: Optional[BrowserContext] = None | ||
| self.context_page: Optional[Page] = None | ||
| self.proxy: Optional[Dict] = None | ||
| self.user_agent = utils.get_user_agent() | ||
| self.dy_client: Optional[DOUYINClient] = None | ||
|
|
||
| def init_config(self, **kwargs): | ||
| self.keywords = kwargs.get("keywords") | ||
| self.scan_qrcode_time = kwargs.get("scan_qrcode_time") | ||
|
|
||
| async def start(self): | ||
| async with async_playwright() as playwright: | ||
| chromium = playwright.chromium | ||
| browser = await chromium.launch(headless=False) | ||
| self.browser_context = await browser.new_context( | ||
| viewport={"width": 1920, "height": 1080}, | ||
| user_agent=self.user_agent, | ||
| proxy=self.proxy | ||
| ) | ||
| # execute JS to bypass anti automation/crawler detection | ||
| await self.browser_context.add_init_script(path="libs/stealth.min.js") | ||
| self.context_page = await self.browser_context.new_page() | ||
| await self.context_page.goto("https://www.douyin.com") | ||
|
|
||
| # scan qrcode login | ||
| await self.login() | ||
| await self.update_cookies() | ||
|
|
||
| # block main crawler coroutine | ||
| await asyncio.Event().wait() | ||
|
|
||
| async def update_cookies(self): | ||
| self.cookies = await self.browser_context.cookies() | ||
|
|
||
| async def login(self): | ||
| pass | ||
|
|
||
| def search_posts(self): | ||
| pass | ||
|
|
||
| def get_comments(self, item_id: str): | ||
| pass |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,2 @@ | ||
| from .core import XiaoHongShuCrawler | ||
| from .field import * |
Oops, something went wrong.