![]()
Building applications with LLMs at the core using our Symbolic API facilitates the integration of classical and differentiable programming in Python.
Read full paper here.
Read further documentation here.






Conceptually, SymbolicAI is a framework that leverages machine learning – specifically LLMs – as its foundation, and composes operations based on task-specific prompting. We adopt a divide-and-conquer approach to break down a complex problem into smaller, more manageable problems. Consequently, each operation addresses a simpler task. By reassembling these operations, we can resolve the complex problem. Moreover, our design principles enable us to transition seamlessly between differentiable and classical programming, allowing us to harness the power of both paradigms.
| Date | Title | Video |
|---|---|---|
| 2nd Dec. 2023 | Use ChatGPT and off-the-shelf RAG on Terminal/Command Prompt/Shell |  |
| 21st Nov. 2023 | Virtual Persona from Documents, Multi-Agent Chat, Text-to-Speech to hear your Personas |  |
| 1st Aug. 2023 | Automatic Retrieval Augmented Generation, Multimodal Inputs, User Packages |  |
| 22nd July 2023 | ChatBot In-Depth Demonstration (Tool Use and Iterative Processing) |  |
| 1st July 2023 | Symbols, Operations, Expressions, LLM-based functions! |  |
| 9th June 2023 | The future is neuro-symbolic: Expressiveness of ChatGPT and generalizability of symbols |  |
- SymbolicAI
- A Neuro-Symbolic Perspective on Large Language Models (LLMs)
- Abstract
- Tutorials
- 📖 Table of Contents
- 🔧 Get Started
- 🦖 Apps
- 🤷♂️ Why SymbolicAI?
- Tell me some more fun facts!
- How Does it Work?
- Operations
- Prompt Design
- 😑 Expressions
- ❌ Error Handling
- 🕷️ Interpretability, Testing & Debugging
▶️ Experiment with Our API- 📈 Interface for Query and Response Inspection
- 🤖 Engines
- ⚡Limitations
- 🥠 Future Work
- Conclusion
- 👥 References, Related Work, and Credits
pip install symbolicaiOne can run our framework in two ways:
- using local engines (
experimental) that are run on your local machine (see Local Neuro-Symbolic Engine section), or - using engines powered by external APIs, i.e. using OpenAI's API (see API Keys).
Before the first run, define exports for the required API keys to enable the respective engines. This will register the keys in internally for subsequent runs. By default SymbolicAI currently uses OpenAI's neural engines, i.e. GPT-3 Davinci-003, DALL·E 2 and Embedding Ada-002, for the neuro-symbolic computations, image generation and embeddings computation respectively. However, these modules can easily be replaced with open-source alternatives. Examples are
- OPT or Bloom for neuro-symbolic computations,
- Craiyon for image generation,
- and any BERT variants for semantic embedding computations.
To set the OpenAI API Keys use the following command:
# Linux / MacOS
export OPENAI_API_KEY="<OPENAI_API_KEY>"
# Windows (PowerShell)
$Env:OPENAI_API_KEY="<OPENAI_API_KEY>"
# Jupyter Notebooks (important: do not use quotes)
%env OPENAI_API_KEY=<OPENAI_API_KEY>To get started import our library by using:
import symai as aiOverall, the following engines are currently supported:
- Neuro-Symbolic Engine: OpenAI's LLMs (supported GPT-3, ChatGPT, GPT-4) (as an experimental alternative using llama.cpp for local models)
- Embedding Engine: OpenAI's Embedding API
- [Optional] Symbolic Engine: WolframAlpha
- [Optional] Search Engine: SerpApi
- [Optional] OCR Engine: APILayer
- [Optional] SpeechToText Engine: OpenAI's Whisper
- [Optional] WebCrawler Engine: Selenium
- [Optional] Image Rendering Engine: DALL·E 2
- [Optional] Indexing Engine: Pinecone
- [Optional] CLIP Engine: 🤗 Hugging Face (experimental image and text embeddings)
SymbolicAI uses multiple engines to process text, speech and images. We also include search engine access to retrieve information from the web. To use all of them, you will need to install also the following dependencies or assign the API keys to the respective engines.
If you want to use the WolframAlpha Engine, Search Engine or OCR Engine you will need to export the following API keys:
# Linux / MacOS
export SYMBOLIC_ENGINE_API_KEY="<WOLFRAMALPHA_API_KEY>"
export SEARCH_ENGINE_API_KEY="<SERP_API_KEY>"
export OCR_ENGINE_API_KEY="<APILAYER_API_KEY>"
export INDEXING_ENGINE_API_KEY="<PINECONE_API_KEY>"
# Windows (PowerShell)
$Env:SYMBOLIC_ENGINE_API_KEY="<WOLFRAMALPHA_API_KEY>"
$Env:SEARCH_ENGINE_API_KEY="<SERP_API_KEY>"
$Env:OCR_ENGINE_API_KEY="<APILAYER_API_KEY>"
$Env:INDEXING_ENGINE_API_KEY="<PINECONE_API_KEY>"To use the optional engines, install the respective extras:
pip install "symbolicai[wolframalpha]"
pip install "symbolicai[whisper]"
pip install "symbolicai[selenium]"
pip install "symbolicai[serpapi]"
pip install "symbolicai[pinecone]"Or, install all optional dependencies at once:
pip install "symbolicai[all]"[Note] Additionally, you need to install the respective codecs.
- SpeechToText Engine:
ffmpegfor audio processing (based on OpenAI's whisper)
# Linux
sudo apt update && sudo apt install ffmpeg
# MacOS
brew install ffmpeg
# Windows
choco install ffmpeg- WebCrawler Engine: For
selenium, we automatically install the driver withchromedriver-autoinstaller. Currently we only support Chrome as the default browser.
Alternatively, you can specify in your project path a symai.config.json file with all the engine properties. This will replace the environment variables. See the following configuration file as an example:
{
"NEUROSYMBOLIC_ENGINE_API_KEY": "<OPENAI_API_KEY>",
"NEUROSYMBOLIC_ENGINE_MODEL": "text-davinci-003",
"SYMBOLIC_ENGINE_API_KEY": "<WOLFRAMALPHA_API_KEY>",
"EMBEDDING_ENGINE_API_KEY": "<OPENAI_API_KEY>",
"EMBEDDING_ENGINE_MODEL": "text-embedding-ada-002",
"IMAGERENDERING_ENGINE_API_KEY": "<OPENAI_API_KEY>",
"VISION_ENGINE_MODEL": "openai/clip-vit-base-patch32",
"SEARCH_ENGINE_API_KEY": "<SERP_API_KEY>",
"SEARCH_ENGINE_MODEL": "google",
"OCR_ENGINE_API_KEY": "<APILAYER_API_KEY>",
"SPEECH_TO_TEXT_ENGINE_MODEL": "base",
"TEXT_TO_SPEECH_ENGINE_MODEL": "tts-1",
"INDEXING_ENGINE_API_KEY": "<PINECONE_API_KEY>",
"INDEXING_ENGINE_ENVIRONMENT": "us-west1-gcp",
"COLLECTION_DB": "ExtensityAI",
"COLLECTION_STORAGE": "SymbolicAI",
"SUPPORT_COMMUNITY": False
}[NOTE]: Our framework allows you to support us train models for local usage by enabling the data collection feature. On application startup we show the terms of services and you can activate or disable this community feature. We do not share or sell your data to 3rd parties and only use the data for research purposes and to improve your user experience. To change this setting you will be prompted with in our setup wizard to enable or disable community support or you can go to the
symai.config.jsonfile located in your home directory of your.symaifolder (i.e.,~/.symai/symai.config.json), and turn it on/off by setting theSUPPORT_COMMUNITYproperty toTrue/Falsevia the config file or the respective environment variable. [NOTE]: By default, the user warnings are enabled. To disable them, exportSYMAI_WARNINGS=0in your environment variables.
We provide a set of useful tools that demonstrate how to interact with our framework and enable package manage. You can access these apps by calling the sym+<shortcut-name-of-app> command in your terminal or PowerShell.
The Shell Command Tool is a basic shell command support tool that translates natural language commands into shell commands. To start the Shell Command Tool, simply run:
symsh "<your-query>"For more information about the tool and available arguments, use the --help flag:
symsh --helpHere is an example of how to use the Shell Command Tool:
$> symsh "PowerShell edit registry entry"
# :Output:
# Set-ItemProperty -Path <path> -Name <name> -Value <value>
$> symsh "Set-ItemProperty -Path <path> -Name <name> -Value <value>" --add "path='/Users/myuser' name=Demo value=SymbolicAI"
# :Output:
# Set-ItemProperty -Path '/Users/myuser' -Name Demo -Value SymbolicAI
$> symsh "Set-ItemProperty -Path '/Users/myuser' -Name Demo -Value SymbolicAI" --del "string quotes"
# :Output:
# Set-ItemProperty -Path /Users/myuser -Name Demo -Value SymbolicAI
$> symsh "Set-ItemProperty -Path '/Users/myuser' -Name Demo -Value SymbolicAI" --convert "linux"
# :Output:
# export Demo="SymbolicAI"symsh is also a regular shell program that interacts with users in the terminal emulation window. It interprets Linux, MacOS, and Windows PowerShell shell commands, and supports ANSI escape sequences.
[NOTE]: Because the colors for the default style is highly dependent on whether the theme is light or dark, they may not be displayed correctly in some terminals. You can change the default style to better fit your needs by modifying the
symsh.config.jsonfile in the.symaidirectory in your home directory (~/.symai/symsh.config.json).
To enter an interactive shell, simply run without any additional parameters:
$> symshThe interactive shell uses the python -m symai.shell feature and runs on top of your existing terminal.
Within the interactive shell you can use your regular shell commands and additionally use the symsh neuro-symbolic commands. The interactive shell supports the following commands:
symsh provides path auto-completion and history auto-completion enhanced by the neuro-symbolic engine. Start typing the path or command, and symsh will provide you with relevant suggestions based on your input and command history.
To trigger a suggestion, press Tab or Ctrl+Space.
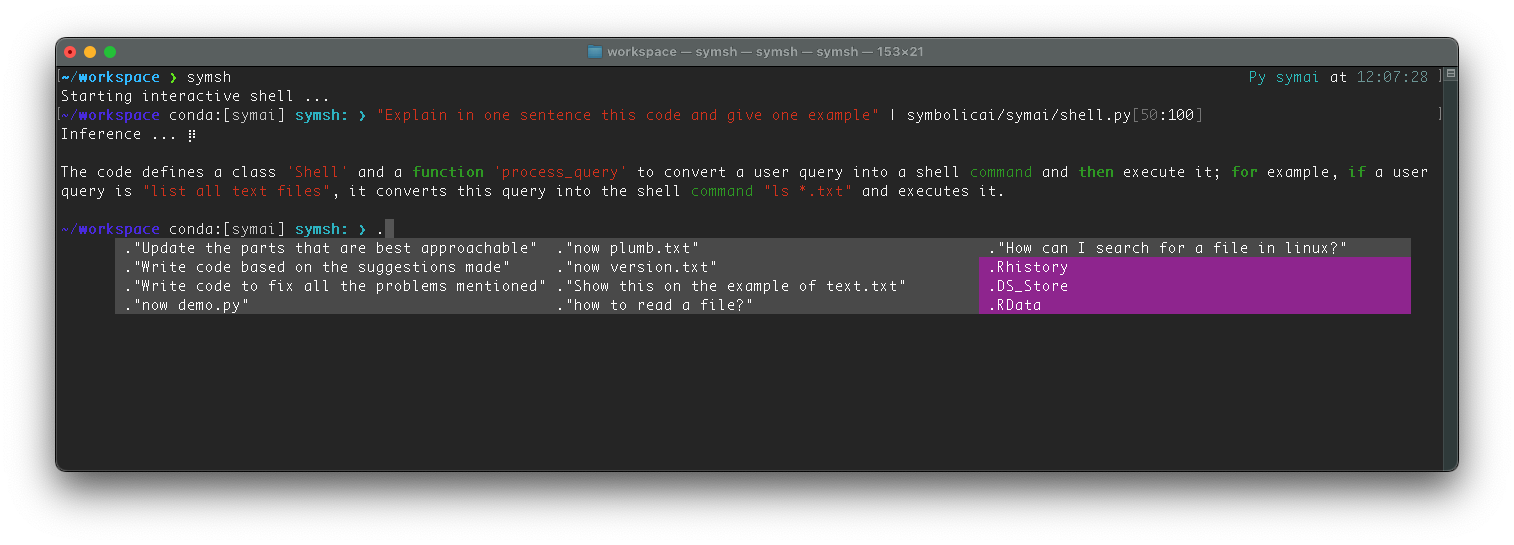
symsh can interact with a language model. By beginning a command with a special character (", ', or `), symsh will treat the command as a query for a language model.
For instance, to make a query, you can type:
$> "What is the capital of France?"
# :Output:
# ParisThe shell command in symsh also has the capability to interact with files using the pipe (|) operator. It operates like a Unix-like pipe but with a few enhancements due to the neuro-symbolic nature of symsh.
Here is the basic usage of the pipe with files:
$> "explain this file" | file_path.txtThis command would instruct the AI to explain the file file_path.txt and consider its contents for the conversation.
The real power of symsh shines through when dealing with large files. symsh extends the typical file interaction by allowing users to select specific sections or slices of a file.
To use this feature, you would need to append the desired slices to the filename within square brackets []. The slices should be comma-separated, and you can apply Python's indexing rules. You can specify a single line, a range of lines, or step indexing.
Here are a few examples:
Single line:
$> "analyze this line" | file_path.txt[10]Range of lines:
# analyze lines 10 to 20
$> "analyze this line" | file_path.txt[10:20]Step indexing:
# analyze lines 10 to 30 with a step size of 3
$> "analyze this line" | file_path.txt[10:30:3]Multi-line indexing:
# analyze lines 10 to 30 with a step size of 3, and lines 40 to 50
$> "analyze this line" | file_path.txt[10:30:3,20,40:50]The above commands would read and include the specified lines from file file_path.txt into the ongoing conversation.
This feature enables you to maintain highly efficient and context-thoughtful conversations with symsh, especially useful when dealing with large files where only a subset of content in specific locations within the file is relevant at any given moment.
The stateful_conversation feature is used for maintaining a continuing conversation with the language model. To use this feature, you have to start your commands with specific symbols in the shell:
-
Creating a new stateful conversation:
Use any of these three symbols at the start of your command:
!",!', or!`. This will initialize a new stateful conversation. If there was a previously saved conversation, these commands will overwrite it. -
Continuing a stateful conversation:
Use one of these three symbols at the start of your command:
.",.', or.`. The command can then be used to continue the most recent stateful conversation. If no previous conversation exists, a new one is created.
Example:
- Starting a new conversation:
!"what is your name" - Continuing the conversation:
."how old are you"
These commands can be used in any shell operation. Keep in mind, stateful conversations are saved and can be resumed later. The shell will save the conversation automatically if you type exit or quit to exit the interactive shell.
Stateful conversation offers the capability to process files as well. If your command contains a pipe (|), the shell will treat the text after the pipe as the name of a file to add it to the conversation.
Example:
$> !"explain this file" | my_file.txtThis command will instruct the AI to explain the file my_file.txt and consider its contents in the conversation. Afterwards you can continue the conversation with:
$> ."what did you mean with ...?"You can engage in a basic conversation with Symbia, a chatbot that uses SymbolicAI to detect the content of your request and switch between different contextual modes to answer your questions. These modes include search engines, speech engines, and more. To start the chatbot, simply run:
$> symchatThis will launch a chatbot interface:
Symbia: Hi there! I'm Symbia, your virtual assistant. How may I help you?
$>To exit the conversation, type exit, quit, or press Ctrl+C.
You can also load our chatbot SymbiaChat into a jupyter notebook and process step-wise requests.
We provide a package manager called sympkg that allows you to manage extensions from the command line. With sympkg, you can install, remove, list installed packages, or update a module.
To use sympkg, follow the steps below:
- Open your terminal or PowerShell.
- Run the following command:
sympkg <command> [<args>]
The available commands are:
iorinstall: Install a new package. To install a package, use the following command:sympkg i <package>rorremove: Remove an installed package. To remove a package, use the following command:sympkg r <package>lorlist: List all installed packages. To list installed packages, use the following command:sympkg luorupdate: Update an installed package. To update a package, use the following command:sympkg u <package>
For more information on each command, you can use the --help flag. For example, to get help on the i command, use the following command: sympkg i --help.
Note: The package manager is based on GitHub, so you will need git installed to install or update packages. The packages names use the GitHub <username>/<repo_name> convention.
Happy package managing!
The Package Runner is a command-line tool that allows you to run packages via alias names. It provides a convenient way to execute commands or functions defined in packages. You can access the Package Runner by using the symrun command in your terminal or PowerShell.
To use the Package Runner, you can run the following command:
$> symrun <alias> [<args>] | <command> <alias> [<package>]The most commonly used Package Runner commands are:
<alias> [<args>]: Run an aliasc <alias> <package>: Create a new aliasl: List all aliasesr <alias>: Remove an alias
Here are a few examples to illustrate how to use the Package Runner:
$> symrun my_alias arg1 arg2 kwarg1=value1 kwarg2=value2This command runs the specified my_alias with the provided arguments arg1, arg2, kwarg1 and kwarg2, where arg1 and arg2 are considered as *args parameter and kwarg1 and kwarg1 **kwargs key-value arguments. These arguments will be passed on to the executable expression within the expression.
$> symrun c my_alias <username>/<repo_name>This command creates a new alias named my_alias that points to <username>/<repo_name>.
$> symrun lThis command lists all the aliases that have been created.
$> symrun r my_aliasThis command removes the alias named my_alias.
The Package Runner stores aliases in a JSON file named aliases.json. This file is located in the .symai/packages/ directory in your home directory (~/.symai/packages/). You can view the contents of this file to see the existing aliases.
Here is an example how to use the sympkg and symrun via shell:
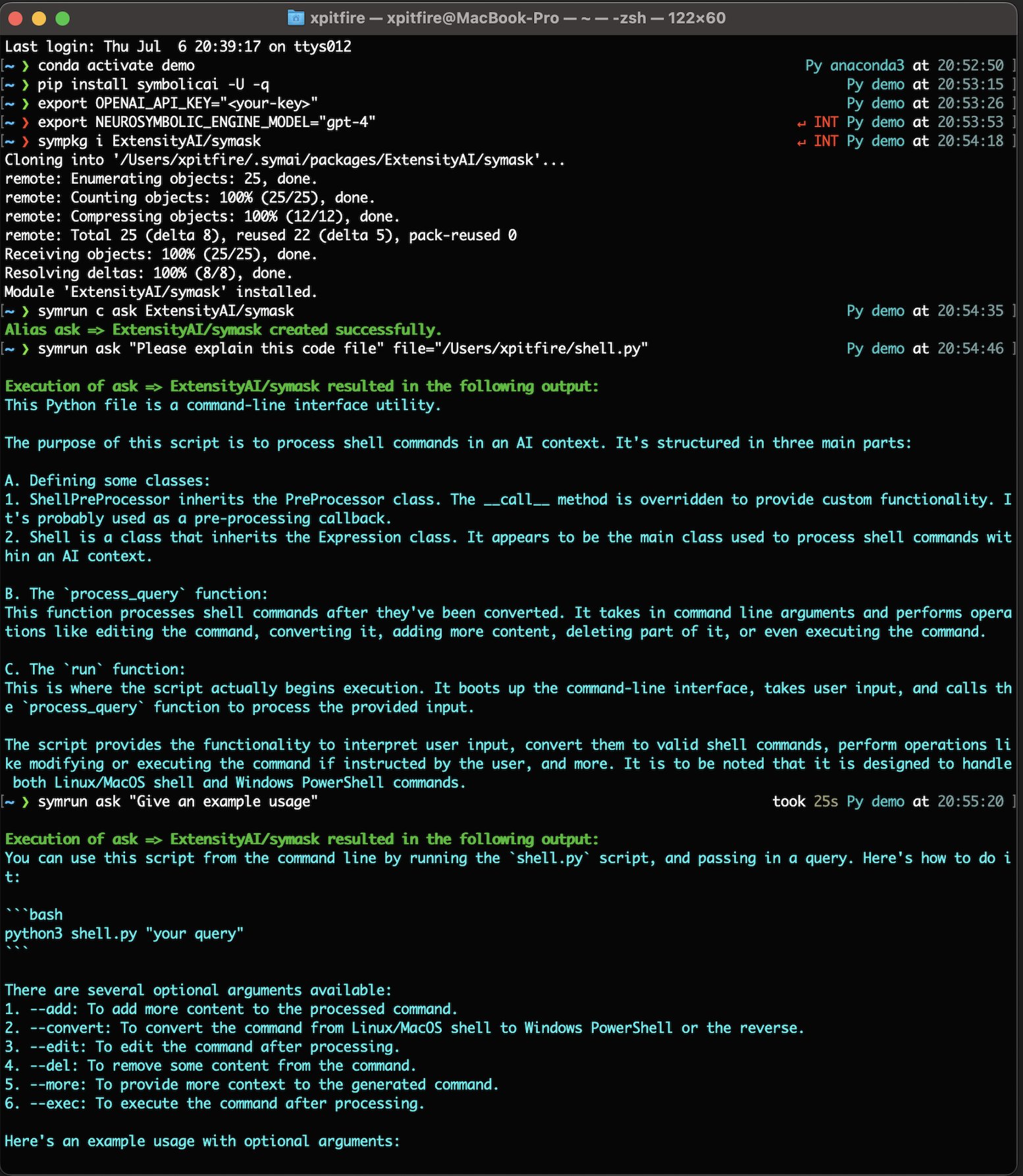
If the alias specified cannot be found in the alias file, the Package Runner will attempt to run the command as a package. If the package is not found or an error occurs during execution, an appropriate error message will be displayed.
That's it! You now have a basic understanding of how to use the Package Runner provided to run packages and aliases from the command line.
The Package Initializer is a command-line tool provided that allows developers to create new GitHub packages from the command line. It automates the process of setting up a new package directory structure and files. You can access the Package Initializer by using the symdev command in your terminal or PowerShell.
To use the Package Initializer, you can run the following command:
$> symdev c <username>/<repo_name>The most commonly used Package Initializer command is:
c <username>/<repo_name>: Create a new package
Here is an example to illustrate how to use the Package Initializer:
$> symdev c symdev/my_packageThis command creates a new package named my_package under the GitHub username symdev.
The Package Initializer creates the following files and directories:
.gitignore: Specifies files and directories that should be ignored by Git.LICENSE: Contains the license information for the package.README.md: Contains the description and documentation for the package.requirements.txt: Lists the packages and dependencies required by the package.package.json: Provides metadata for the package, including version, name, description, and expressions.src/func.py: Contains the main function and expression code for the package.
The Package Initializer creates the package in the .symai/packages/ directory in your home directory (~/.symai/packages/<username>/<repo_name>).
Within the created package you will see the package.json config file defining the new package metadata and symrun entry point and offers the declared expression types to the Import class.
The Import class is a module management class in the SymbolicAI library. This class provides an easy and controlled way to manage the use of external modules in the user’s project, with main functions including the ability to install, uninstall, update, and check installed modules. It is used to manage expression loading from packages and accesses the respective metadata from the package.json.
The metadata for the package includes version, name, description, and expressions. It also lists the package dependencies required by the package.
Here is an example of a package.json file:
{
"version": "0.0.1",
"name": "<username>/<repo_name>",
"description": "<Project Description>",
"expressions": [{"module": "src/func", "type": "MyExpression"}],
"run": {"module": "src/func", "type": "MyExpression"},
"dependencies": []
}version: Specifies the version number of the package. It is recommended to follow semantic versioning.name: Specifies the name of the package. It typically follows the format<username>/<repo_name>, where<username>is your GitHub username and<repo_name>is the name of your package repository.description: Provides a brief description of the package.expressions: Defines the exported expressions for the package. Each expression is defined by itsmoduleandtype. Themodulespecifies the file path or module name where the expression is defined, and thetypespecifies the type of the expression. These are used to be accessed from code by calling `Import.run: Specifies the expression that should be executed when the package is run. It follows the same format as theexpressionsproperty, only defined by a single entry point type.dependencies: Lists the package dependencies to other SymbolicAI packages! Dependencies can be specified with their package name<username>/<repo_name>.
Note that the package.json file is automatically created when you use the Package Initializer tool (symdev) to create a new package. Alongside the package.json also a requirements.txt is created. This file contains all the pip relevant dependencies.
To import a package from code, see the following example:
from symai import Import
symask_module = Import("ExtensityAI/symask")This command will clone the module from the given GitHub repository (ExtensityAI/symask in this case), install any dependencies, and expose the module's classes for use in your project.
You can also install a module without instantiating it using the install method:
Import.install("ExtensityAI/symask")The Import class will automatically handle the cloning of the repository and the installation of dependencies that are declared in the package.json and requirements.txt files of the repository.
Please refer to the comments in the code for more detailed explanations of how each method of the Import class works.
We have compiled several examples to demonstrate the use of our Symbolic API. These can be found in the notebooks folder.
- Basics: Explore the basics notebook to become familiar with our API structure (notebooks/Basics.ipynb)
- Queries: Learn about query manipulation in our notebook on contextualized operations (notebooks/Queries.ipynb)
- News & Docs Generation: Discover stream processing in our news and documentation generation notebook (notebooks/News.ipynb)
- ChatBot: Learn how to implement a custom chatbot based on semantic narrations (notebooks/ChatBot.ipynb)
You can solve numerous problems with our Symbolic API. We look forward to seeing what you create! Share your work in our community space on Discord: AI Is All You Need / SymbolicAI.
We are showcasing the exciting demos and tools created using our framework. If you want to add your project, feel free to message us on Twitter at @SymbolicAPI or via Discord.
SymbolicAI aims to bridge the gap between classical programming, or Software 1.0, and modern data-driven programming (aka Software 2.0). It is a framework designed to build software applications that leverage the power of large language models (LLMs) with composability and inheritance, two potent concepts in the object-oriented classical programming paradigm.
By using SymbolicAI, you can traverse the spectrum between the classical programming realm and the data-driven programming realm, as illustrated in the following figure:

We adopt a divide-and-conquer approach, breaking down complex problems into smaller, manageable tasks. We use the expressiveness and flexibility of LLMs to evaluate these sub-problems. By re-combining the results of these operations, we can solve the broader, more complex problem.
In time, and with sufficient data, we can gradually transition from general-purpose LLMs with zero and few-shot learning capabilities to specialized, fine-tuned models designed to solve specific problems (see above). This strategy enables the design of operations with fine-tuned, task-specific behavior.

SymbolicAI is fundamentally inspired by the neuro-symbolic programming paradigm.
Neuro-symbolic programming is an artificial intelligence and cognitive computing paradigm that combines the strengths of deep neural networks and symbolic reasoning.
Deep neural networks are machine learning algorithms inspired by the structure and function of biological neural networks. They excel in tasks such as image recognition and natural language processing. However, they struggle with tasks that necessitate explicit reasoning, like long-term planning, problem-solving, and understanding causal relationships.
Symbolic reasoning uses formal languages and logical rules to represent knowledge, enabling tasks such as planning, problem-solving, and understanding causal relationships. While symbolic reasoning systems excel in tasks requiring explicit reasoning, they fall short in tasks demanding pattern recognition or generalization, like image recognition or natural language processing.
Neuro-symbolic programming aims to merge the strengths of both neural networks and symbolic reasoning, creating AI systems capable of handling various tasks. This combination is achieved by using neural networks to extract information from data and utilizing symbolic reasoning to make inferences and decisions based on that data. Another approach is for symbolic reasoning to guide the neural networks' generative process and increase interpretability.
Embedded accelerators for LLMs will likely be ubiquitous in future computation platforms, including wearables, smartphones, tablets, and notebooks. These devices will incorporate models similar to GPT-3, ChatGPT, OPT, or Bloom.

LLMs are expected to perform a wide range of computations, like natural language understanding and decision-making. Additionally, neuro-symbolic computation engines will learn how to tackle unseen tasks and resolve complex problems by querying various data sources for solutions and executing logical statements on top. To ensure the content generated aligns with our objectives, it is crucial to develop methods for instructing, steering, and controlling the generative processes of machine learning models. As a result, our approach works to enable active and transparent flow control of these generative processes.

The figure above depicts this generative process as shifting the probability mass of an input stream toward an output stream in a contextualized manner. With properly designed conditions and expressions, you can validate and guide the behavior towards a desired outcome or repeat expressions that fail to meet requirements. Our approach consists of defining a set of fuzzy operations to manipulate the data stream and condition LLMs to align with our goals. We regard all data objects – such as strings, letters, integers, and arrays – as symbols and view natural language as the primary interface for interaction. See the following figure:
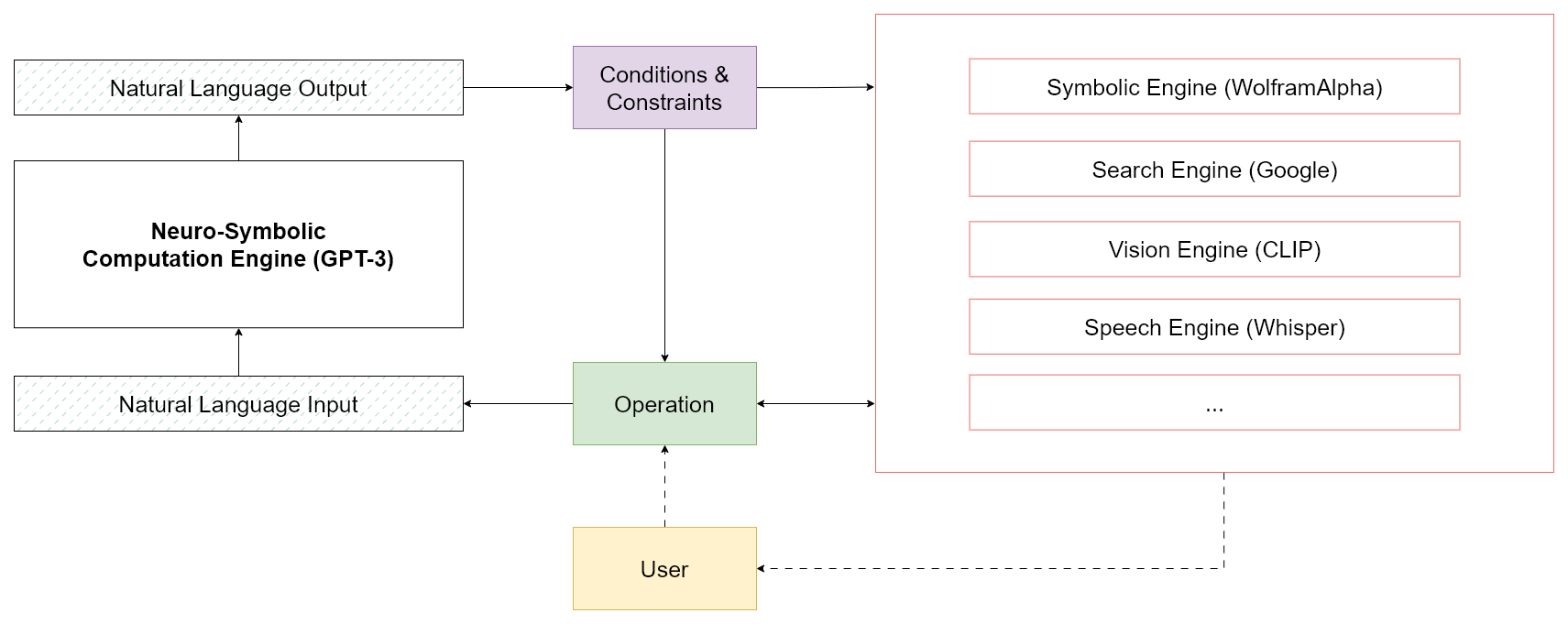
As long as our goals can be expressed through natural language, LLMs can be used for neuro-symbolic computations. Consequently, we develop operations that manipulate these symbols to construct new symbols. Each symbol can be interpreted as a statement, and multiple statements can be combined to formulate a logical expression.
By combining statements together, we can build causal relationship functions and complete computations, transcending reliance purely on inductive approaches. The resulting computational stack resembles a neuro-symbolic computation engine at its core, facilitating the creation of new applications in tandem with established frameworks.
We will now demonstrate how we define our Symbolic API, which is based on object-oriented and compositional design patterns. The Symbol class serves as the base class for all functional operations, and in the context of symbolic programming (fully resolved expressions), we refer to it as a terminal symbol. The Symbol class contains helpful operations that can be interpreted as expressions to manipulate its content and evaluate new Symbols.
Let's define a Symbol and perform some basic manipulations. We begin with a translation operation:
sym = ai.Symbol("Welcome to our tutorial.")
sym.translate('German')Output:
<class 'symai.expressions.Symbol'>(value=Willkommen zu unserem Tutorial.)Our API can also execute basic data-agnostic operations like filter, rank, or extract patterns. For instance, we can rank a list of numbers:
sym = ai.Symbol(numpy.array([1, 2, 3, 4, 5, 6, 7]))
res = sym.rank(measure='numerical', order='descending')Output:
<class 'symai.expressions.Symbol'>(value=['7', '6', '5', '4', '3', '2', '1'])Evaluations are resolved in the language domain and by best effort. We showcase this on the example of word2vec.
Word2Vec generates dense vector representations of words by training a shallow neural network to predict a word based on its neighbors in a text corpus. These resulting vectors are then employed in numerous natural language processing applications, such as sentiment analysis, text classification, and clustering.
In the example below, we can observe how operations on word embeddings (colored boxes) are performed. Words are tokenized and mapped to a vector space where semantic operations can be executed using vector arithmetic.
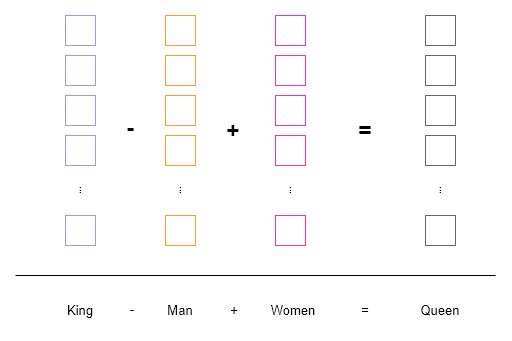
Similar to word2vec, we aim to perform contextualized operations on different symbols. However, as opposed to operating in vector space, we work in the natural language domain. This provides us the ability to perform arithmetic on words, sentences, paragraphs, etc., and verify the results in a human-readable format.
The following examples display how to evaluate such an expression using a string representation:
ai.Symbol('King - Man + Women').expression()Output:
<class 'symai.expressions.Symbol'>(value=Queen)We can also subtract sentences from one another, where our operations condition the neural computation engine to evaluate the Symbols by their best effort. In the subsequent example, it identifies that the word enemy is present in the sentence, so it deletes it and replaces it with the word friend (which is added):
res = ai.Symbol('Hello my enemy') - 'enemy' + 'friend'Output:
<class 'symai.expressions.Symbol'>(value=Hello my friend)Additionally, the API performs dynamic casting when data types are combined with a Symbol object. If an overloaded operation of the Symbol class is employed, the Symbol class can automatically cast the second object to a Symbol. This is a convenient way to perform operations between Symbol objects and other data types, such as strings, integers, floats, lists, etc., without cluttering the syntax.
In this example, we perform a fuzzy comparison between two numerical objects. The Symbol variant is an approximation of numpy.pi. Despite the approximation, the fuzzy equals == operation still successfully compares the two values and returns True.
sym = ai.Symbol('3.1415...')
sym == numpy.pi:[Output]:
TrueThe main goal of our framework is to enable reasoning capabilities on top of the statistical inference of Language Models (LMs). As a result, our Symbol objects offers operations to perform deductive reasoning expressions. One such operation involves defining rules that describe the causal relationship between symbols. The following example demonstrates how the & operator is overloaded to compute the logical implication of two symbols.
res = ai.Symbol('The horn only sounds on Sundays.') & ai.Symbol('I hear the horn.'):[Output]:
<class 'symai.expressions.Symbol'>(value=It is Sunday.)The current & operation overloads the and logical operator and sends few-shot prompts to the neural computation engine for statement evaluation. However, we can define more sophisticated logical operators for and, or, and xor using formal proof statements. Additionally, the neural engines can parse data structures prior to expression evaluation. Users can also define custom operations for more complex and robust logical operations, including constraints to validate outcomes and ensure desired behavior.
To provide a more comprehensive understanding, we present several causal examples below. These examples aim to obtain logical answers based on questions like:
# 1) "A line parallel to y = 4x + 6 passes through (5, 10). What is the y-coordinate of the point where this line crosses the y-axis?"
# 2) "Bob has two sons, John and Jay. Jay has one brother and father. The father has two sons. Jay's brother has a brother and a father. Who is Jay's brother?"
# 3) "Is 1000 bigger than 1063.472?"An example approach using our framework would involve identifying the neural engine best suited for the task and preparing the input for that engine. Here's how we could achieve this:
val = "<one of the examples above>"
# First, define a class that inherits from the Expression class
class ComplexExpression(ai.Expression): # more on the Expression class in later sections
# write a method that returns the causal evaluation
def causal_expression(self):
pass # see below for implementation
# instantiate an object of the class
expr = ComplexExpression(val)
# set WolframAlpha as the main expression engine to use
wolfram = ai.Interface('wolframalpha')
# evaluate the expression
res = expr.causal_expression()A potential implementation of the causal_expression method could resemble the following:
def causal_expression(self):
# verify which case to use based on `self.value`
if self.isinstanceof('mathematics'):
# get the mathematical formula
formula = self.extract('mathematical formula')
# verify the problem type
if formula.isinstanceof('linear function'):
# prepare for WolframAlpha
question = self.extract('question sentence')
req = question.extract('what is requested?')
x = self.extract('coordinate point (.,.)') # get the coordinate point / could also ask for other points
query = formula | f', point x = {x}' | f', solve {req}' # concatenate the question and formula
res = wolfram(query) # send the prepared query to WolframAlpha
elif formula.isinstanceof('number comparison'):
res = wolfram(formula) # send directly to WolframAlpha
... # more cases
elif self.isinstanceof('linguistic problem'):
sentences = self / '.' # first, split into sentences
graph = {} # define the graph
for s in sentences:
sym = ai.Symbol(s)
relations = sym.extract('connected entities (e.g., A has three B => A | A: three B)') / '|' # and split by pipe
for r in relations:
... # add relations and populate the graph, or alternatively, learn about CycleGT
... # more cases
return resIn the example above, the causal_expression method iteratively extracts information, enabling manual resolution or external solver usage.
Attention: Keep in mind that this implementation sketch requires significantly more engineering effort for the causal_expression method. Additionally, the current GPT-3 LLM backend may sometimes struggle to extract accurate information or make the correct comparison. However, we believe that future advances in the field, specifically fine-tuned models like ChatGPT with Reinforcement Learning from Human Feedback (RLHF), will improve these capabilities.
Lastly, with sufficient data, we could fine-tune methods to extract information or build knowledge graphs using natural language. This advancement would allow the performance of more complex reasoning tasks, like those mentioned above. Therefore, we recommend exploring recent publications on Text-to-Graphs. In this approach, answering the query involves simply traversing the graph and extracting the necessary information.
In the next section, we will explore operations.
Operations form the core of our framework and serve as the building blocks of our API. These operations define the behavior of symbols by acting as contextualized functions that accept a Symbol object and send it to the neuro-symbolic engine for evaluation. Operations then return one or multiple new objects, which primarily consist of new symbols but may include other types as well. Polymorphism plays a crucial role in operations, allowing them to be applied to various data types such as strings, integers, floats, and lists, with different behaviors based on the object instance.
Operations are executed using the Symbol object's value attribute, which contains the original data type converted into a string representation and sent to the engine for processing. As a result, all values are represented as strings, requiring custom objects to define a suitable __str__ method for conversion while preserving the object's semantics.
Inheritance is another essential aspect of our API, which is built on the Symbol class as its base. All operations are inherited from this class, offering an easy way to add custom operations by subclassing Symbol while maintaining access to basic operations without complicated syntax or redundant functionality. Subclassing the Symbol class allows for the creation of contextualized operations with unique constraints and prompt designs by simply overriding the relevant methods. However, it is recommended to subclass the Expression class for additional functionality.
Defining custom operations can be done through overriding existing Python methods and providing a custom prompt object with example code. Here is an example of creating a custom == operation by overriding the __eq__ method:
class Demo(ai.Symbol):
def __eq__(self, other) -> bool:
@ai.equals(examples=ai.Prompt([
"1 == 'ONE' =>True",
"'six' == 7 =>False",
"'Acht' == 'eight' =>True",
...
])
)
def _func(_, other) -> bool:
return False # default behavior on failure
return _func(self, other)Basic operations in Symbol are implemented by defining local functions and decorating them with corresponding operation decorators from the symai/core.py file, a collection of predefined operation decorators that can be applied rapidly to any function. Using local functions instead of decorating main methods directly avoids unnecessary communication with the neural engine and allows for default behavior implementation. It also helps cast operation return types to symbols or derived classes, using the self.sym_return_type(...) method for contextualized behavior based on the determined return type. More details can be found in the Symbol class.
The following section demonstrates that most operations in symai/core.py are derived from the more general few_shot decorator.
Defining custom operations is also possible, such as creating an operation to generate a random integer between 0 and 10:
class Demo(ai.Expression):
def __init__(self, value = '', **kwargs) -> None:
super().__init__(value, **kwargs)
@ai.zero_shot(prompt="Generate a random integer between 0 and 10.",
constraints=[
lambda x: x >= 0,
lambda x: x <= 10
])
def get_random_int(self) -> int:
passThe Symbolic API employs Python Decorators to define operations, utilizing the @ai.zero_shot decorator to create custom operations that do not require demonstration examples when the prompt is self-explanatory. In this example, the zero_shot decorator accepts two arguments: prompt and constraints. The former defines the prompt dictating the desired operation behavior, while the latter establishes validation constraints for the computed outcome, ensuring it meets expectations.
If a constraint is not satisfied, the implementation will utilize the specified default fallback or default value. If neither is provided, the Symbolic API will raise a ConstraintViolationException. The return type is set to int in this example, so the value from the wrapped function will be of type int. The implementation uses auto-casting to a user-specified return data type, and if casting fails, the Symbolic API will raise a ValueError. If no return type is specified, the return type defaults to Any.
The @ai.few_shot decorator is a generalized version of the @ai.zero_shot decorator, used to define custom operations that require demonstration examples. To provide a clearer understanding, we present the function signature of the few_shot decorator:
def few_shot(prompt: str,
examples: Prompt,
constraints: List[Callable] = [],
default: Optional[object] = None,
limit: int = 1,
pre_processors: Optional[List[PreProcessor]] = None,
post_processors: Optional[List[PostProcessor]] = None,
**decorator_kwargs):The prompt and constraints attributes behave similarly to those in the zero_shot decorator. The examples and limit arguments are new. The examples argument defines a list of demonstrations used to condition the neural computation engine, while the limit argument specifies the maximum number of examples returned, given that there are more results. The pre_processors argument accepts a list of PreProcessor objects for pre-processing input before it's fed into the neural computation engine. The post_processors argument accepts a list of PostProcessor objects for post-processing output before returning it to the user. Lastly, the decorator_kwargs argument passes additional arguments from the decorator kwargs, which are streamlined towards the neural computation engine and other engines.
To provide a more comprehensive understanding of our conceptual implementation, refer to the flow diagram below, containing the most important classes:

The colors indicate logical groups of data processing steps. Yellow represents input and output data, blue shows places where one can customize or prepare the input of the engine, green indicates post-processing steps of the engine response, red displays the application of constraints (including attempted casting of the return type signature if specified in the decorated method), and grey denotes the custom method defining all properties, thus having access to all the previously mentioned objects.
To conclude this section, here is an example of how to write a custom Japanese name generator using our @ai.zero_shot decorator:
import symai as ai
class Demo(ai.Symbol):
@ai.few_shot(prompt="Generate Japanese names: ",
examples=ai.Prompt(
["愛子", "和花", "一郎", "和枝"]
),
limit=2,
constraints=[lambda x: len(x) > 1])
def generate_japanese_names(self) -> list:
return ['愛子', '和花'] # dummy implementationIf the neural computation engine cannot compute the desired outcome, it will revert to the default implementation or default value. If no default implementation or value is found, the method call will raise an exception.
The Prompt class is used to perform all the above operations. Acting as a container for information required to define a specific operation, the Prompt class also serves as the base class for all other Prompt classes.
Here's an example of defining a Prompt to enforce the neural computation engine to compare two values:
class CompareValues(ai.Prompt):
def __init__(self) -> ai.Prompt:
super().__init__([
"4 > 88 =>False",
"-inf < 0 =>True",
"inf > 0 =>True",
"4 > 3 =>True",
"1 < 'four' =>True",
...
])When calling the <= operation on two Symbols, the neural computation engine evaluates the symbols in the context of the CompareValues prompt.
res = ai.Symbol(1) <= ai.Symbol('one')This statement evaluates to True since the fuzzy compare operation conditions the engine to compare the two Symbols based on their semantic meaning.
:[Output]:
TrueIn general, the semantics of Symbol operations may vary depending on the context hierarchy of the expression class and the operations used. To better illustrate this, we display our conceptual prompt design in the following figure:
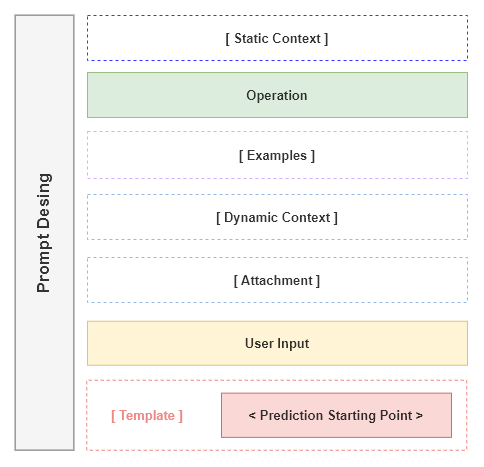
The figure illustrates the hierarchical prompt design as a container for information provided to the neural computation engine to define a task-specific operation. The yellow and green highlighted boxes indicate mandatory string placements, dashed boxes represent optional placeholders, and the red box marks the starting point of model prediction.
Three main prompt designs are considered: Context-based Prompts, Operational Prompts, and Templates. Prompts can be curated either by inheritance or composition. For example, Static Context can be defined by inheriting the Expression class and overriding the static_context property. An Operation and Template prompt can be created by providing a PreProcessor to modify input data.
Each prompt concept is explained in more detail below:
-
Context-based Prompts (Static, Dynamic, and Payload)are considered optional and can be defined either statically (by subclassing the Expression class and overriding thestatic_contextproperty) or at runtime (by updating thedynamic_contextproperty or passingpayloadkwargs to a method). As an example of using thepayloadkwargs via method signature:# creating a query to ask if an issue was resolved or not sym = Symbol("<some-community-conversation>") q = sym.query("Was the issue resolved?") # write manual condition to check if the issue was resolved if 'not resolved' in q: # do a new query but payload the previous query answer to the new query sym.query("What was the resolution?", payload=q) ... else: pass # all good
Regardless of how the context is set, the contextualized prompt defines the desired behavior of Expression operations. For example, one can operate within a domain-specific language context without having to override each base class method. See more details in this notebook.
-
Operationprompts define the behavior of atomic operations and are mandatory to express the nature of such operations. For example, the+operation is used to add two Symbols together, so its prompt explains this behavior.Examplesprovide an optional structure giving the neural computation engine a set of demonstrations used to condition it properly. For instance, the+operation prompt can be conditioned on adding numbers by providing demonstrations like1 + 1 = 2,2 + 2 = 4, etc. -
Templateprompts are optional and encapsulate the resulting prediction to enforce a specific format. For example, to generate HTML tags, one can use the curated<html>{{placeholder}}</html>template. This template ensures that the neural computation engine starts the generation process within the context of an HTML tag format, avoiding the production of irrelevant descriptions regarding its task.
An Expression is a non-terminal symbol that can be further evaluated. It inherits all the properties from the Symbol class and overrides the __call__ method to evaluate its expressions or values. All other expressions are derived from the Expression class, which also adds additional capabilities, such as the ability to fetch data from URLs, search on the internet, or open files. These operations are specifically separated from the Symbol class as they do not use the value attribute of the Symbol class.
SymbolicAI's API closely follows best practices and ideas from PyTorch, allowing the creation of complex expressions by combining multiple expressions as a computational graph. Each Expression has its own forward method that needs to be overridden. The forward method is used to define the behavior of the expression. It is called by the __call__ method, which is inherited from the Expression base class. The __call__ method evaluates an expression and returns the result from the implemented forward method. This design pattern evaluates expressions in a lazy manner, meaning the expression is only evaluated when its result is needed. It is an essential feature that allows us to chain complex expressions together. Numerous helpful expressions can be imported from the symai.components file.
Other important properties inherited from the Symbol class include sym_return_type and static_context. These two properties define the context in which the current Expression operates, as described in the Prompt Design section. The static_context influences all operations of the current Expression sub-class. The sym_return_type ensures that after evaluating an Expression, we obtain the desired return object type. It is usually implemented to return the current type but can be set to return a different type.
Expressions may have more complex structures and can be further sub-classed, as shown in the Sequence expression example in the following figure:
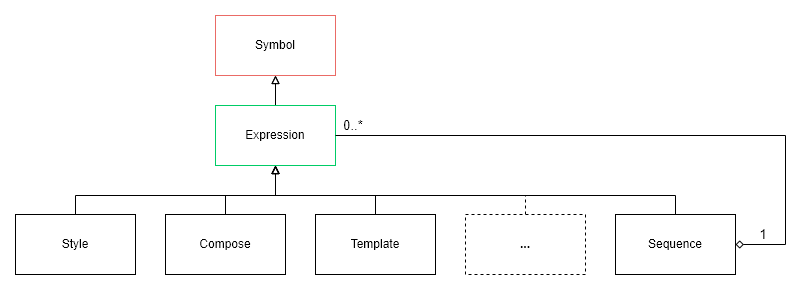
A Sequence expression can hold multiple expressions evaluated at runtime.
Here is an example of defining a Sequence expression:
# First import all expressions
from symai.components import *
# Define a sequence of expressions
Sequence(
Clean(),
Translate(),
Outline(),
Compose('Compose news:'),
)As previously mentioned, we can create contextualized prompts to define the behavior of operations on our neural engine. However, this limits the available context size due to GPT-3 Davinci's context length constraint of 4097 tokens. This issue can be addressed using the Stream processing expression, which opens a data stream and performs chunk-based operations on the input stream.
A Stream expression can be wrapped around other expressions. For example, the chunks can be processed with a Sequence expression that allows multiple chained operations in a sequential manner. Here is an example of defining a Stream expression:
Stream(Sequence(
Clean(),
Translate(),
Outline(),
Embed()
))The example above opens a stream, passes a Sequence object which cleans, translates, outlines, and embeds the input. Internally, the stream operation estimates the available model context size and breaks the long input text into smaller chunks, which are passed to the inner expression. The returned object type is a generator.
This approach has the drawback of processing chunks independently, meaning there is no shared context or information among chunks. To address this issue, the Cluster expression can be used, where the independent chunks are merged based on their similarity, as illustrated in the following figure:
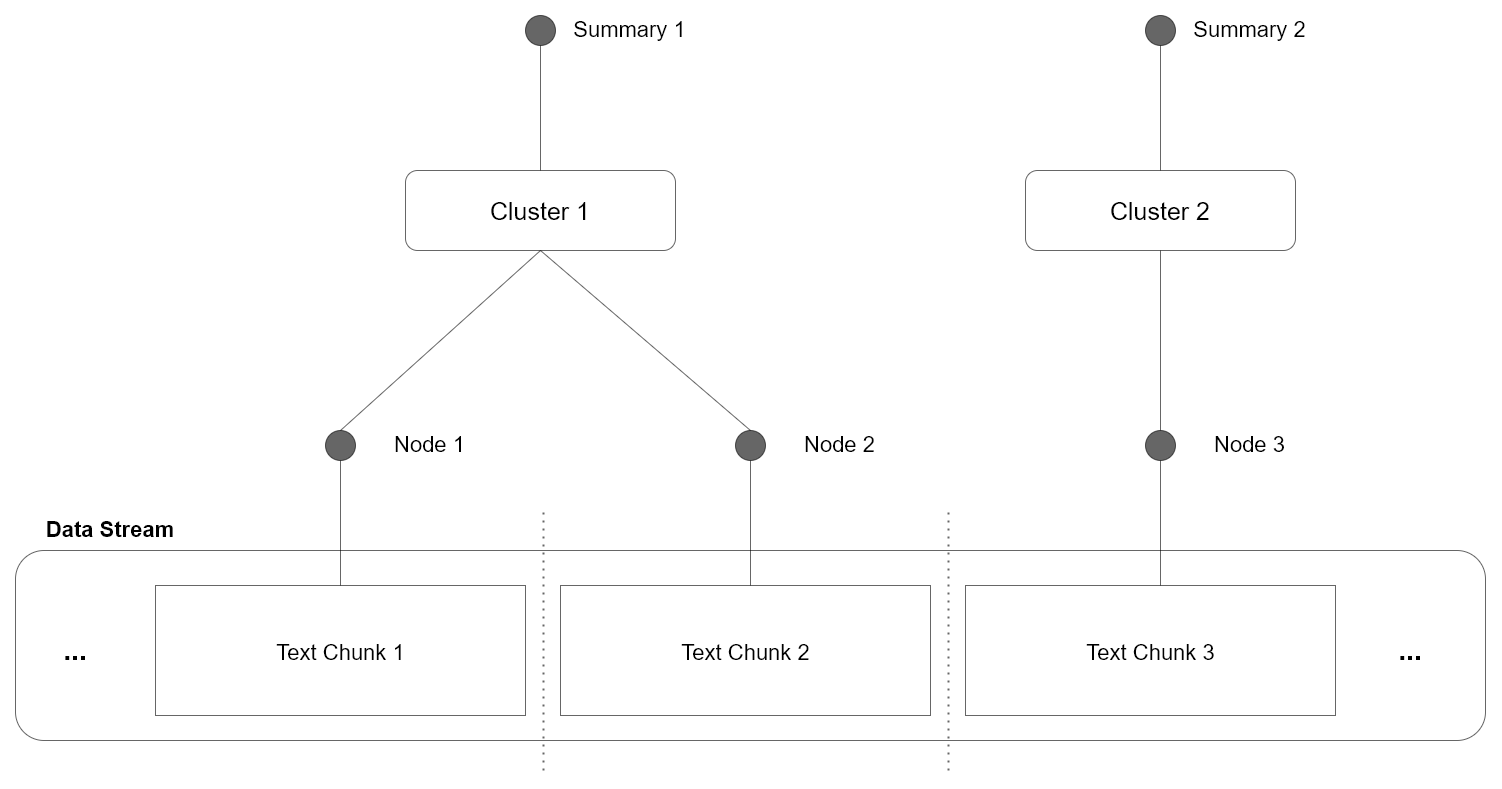
In the illustrated example, all individual chunks are merged by clustering the information within each chunk. It consolidates contextually related information, merging them meaningfully. The clustered information can then be labeled by streaming through the content of each cluster and extracting the most relevant labels, providing interpretable node summaries.
The full example is shown below:
stream = Stream(Sequence(
Clean(),
Translate(),
Outline(),
))
sym = Symbol('<some long text>')
res = Symbol(list(stream(sym)))
expr = Cluster()
expr(res)Next, we could recursively repeat this process on each summary node, building a hierarchical clustering structure. Since each Node resembles a summarized subset of the original information, we can use the summary as an index. The resulting tree can then be used to navigate and retrieve the original information, transforming the large data stream problem into a search problem.
Alternatively, vector-based similarity search can be used to find similar nodes. Libraries such as Annoy, Faiss, or Milvus can be employed for searching in a vector space.
A key idea of the SymbolicAI API is code generation, which may result in errors that need to be handled contextually. In the future, we want our API to self-extend and resolve issues automatically. We propose the Try expression, which has built-in fallback statements and retries an execution with dedicated error analysis and correction. The expression analyzes the input and error, conditioning itself to resolve the error by manipulating the original code. If the fallback expression succeeds, the result is returned. Otherwise, this process is repeated for the specified number of retries. If the maximum number of retries is reached and the problem remains unresolved, the error is raised again.
Suppose we have some executable code generated previously. By the nature of generative processes, syntax errors may occur. Using the Execute expression, we can evaluate our generated code, which takes in a symbol and tries to execute it. Naturally, this will fail. However, in the following example, the Try expression resolves the syntax error, and we receive a computed result.
expr = Try(expr=Execute())
sym = Symbol('a = int("3,")') # Some code with a syntax error
res = expr(sym)The resulting output is the corrected, evaluated code:
:Output:
a = 3We are aware that not all errors are as simple as the syntax error example shown, which can be resolved automatically. Many errors occur due to semantic misconceptions, requiring contextual information. We are exploring more sophisticated error handling mechanisms, including the use of streams and clustering to resolve errors in a hierarchical, contextual manner. It is also important to note that neural computation engines need further improvements to better detect and resolve errors.
Perhaps one of the most significant advantages of using neuro-symbolic programming is that it allows for a clear understanding of how well our LLMs comprehend simple operations. Specifically, we gain insight into whether and at what point they fail, enabling us to follow their StackTraces and pinpoint the failure points. In our case, neuro-symbolic programming enables us to debug the model predictions based on dedicated unit tests for simple operations. To detect conceptual misalignments, we can use a chain of neuro-symbolic operations and validate the generative process. Although not a perfect solution, as the verification might also be error-prone, it provides a principled way to detect conceptual flaws and biases in our LLMs.
Since our approach is to divide and conquer complex problems, we can create conceptual unit tests and target very specific and tractable sub-problems. The resulting measure, i.e., the success rate of the model prediction, can then be used to evaluate their performance and hint at undesired flaws or biases.
This method allows us to design domain-specific benchmarks and examine how well general learners, such as GPT-3, adapt with certain prompts to a set of tasks.
For example, we can write a fuzzy comparison operation that can take in digits and strings alike and perform a semantic comparison. LLMs can then be asked to evaluate these expressions. Often, these LLMs still fail to understand the semantic equivalence of tokens in digits vs. strings and provide incorrect answers.
The following code snippet shows a unit test to perform semantic comparison of numbers (between digits and strings):
import unittest
from symai import *
class TestComposition(unittest.TestCase):
def test_compare(self):
res = Symbol(10) > Symbol(5)
self.assertTrue(res)
res = Symbol(1) < Symbol('five')
self.assertTrue(res)
...When creating complex expressions, we debug them by using the Trace expression, which allows us to print out the applied expressions and follow the StackTrace of the neuro-symbolic operations. Combined with the Log expression, which creates a dump of all prompts and results to a log file, we can analyze where our models potentially failed.
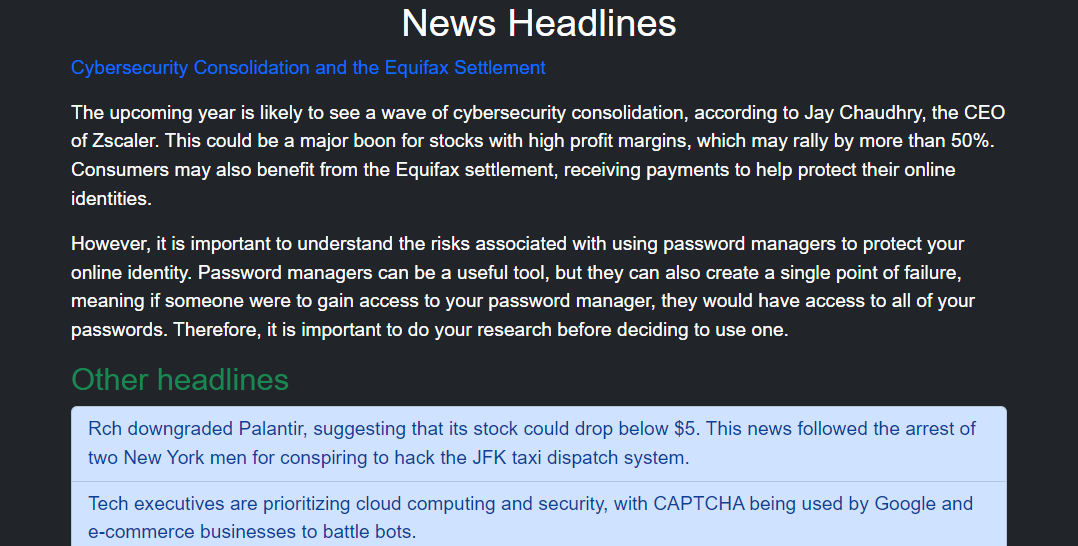
In the following example, we create a news summary expression that crawls the given URL and streams the site content through multiple expressions. The outcome is a news website created based on the crawled content. The Trace expression allows us to follow the StackTrace of the operations and observe which operations are currently being executed. If we open the outputs/engine.log file, we can see the dumped traces with all the prompts and results.
# crawling the website and creating a website based on its facts
news = News(url='https://www.cnbc.com/cybersecurity/',
pattern='cnbc',
filters=ExcludeFilter('sentences about subscriptions, licensing, newsletter'),
render=True)
expr = Log(Trace(news))
res = expr()Here is the corresponding StackTrace of the model:

The above code creates a webpage with the crawled content from the original source. See the preview below, the entire rendered webpage image here, and the resulting code of the webpage here.
{kind=link}
Launch and explore the notebook here:
Find more examples in the examples folder and the notebooks folder. You can also examine the test cases in the tests folder.
SymbolicAI is a data-driven framework by design. This implies that we can gather data from API interactions while delivering the requested responses. For rapid, dynamic adaptations or prototyping, we can swiftly integrate user-desired behavior into existing prompts. Moreover, we can log user queries and model predictions to make them accessible for post-processing. Consequently, we can enhance and tailor the model's responses based on real-world data.
In the example below, we demonstrate how to use an Output expression to pass a handler function and access the model's input prompts and predictions. These can be utilized for data collection and subsequent fine-tuning stages. The handler function supplies a dictionary and presents keys for input and output values. The content can then be sent to a data pipeline for additional processing.
sym = Symbol('Hello World!')
def handler(res):
input_ = res['input']
output = res['output']
expr = Output(expr=sym.translate,
handler=handler,
verbose=True)
res = expr('German')Since we used verbose, the console print of the Output expression is also visible:
Input: (['Translate the following text into German:\n\nHello World!'],)
Expression: <bound method Symbol.translate of <class 'symai.symbol.Symbol'>(value=Hello World!)>
args: ('German',) kwargs: {'input_handler': <function OutputEngine.forward.<locals>.input_handler at ...
Dictionary: {'instance': <class 'symai.components.Output'>(value=None), 'func': <function Symbol.output.<locals>._func at ...
Output: Hallo Welt!Due to limited computing resources, we currently utilize OpenAI's GPT-3, ChatGPT and GPT-4 API for the neuro-symbolic engine. However, given adequate computing resources, it is feasible to use local machines to reduce latency and costs, with alternative engines like OPT or Bloom. This would enable recursive executions, loops, and more complex expressions.
Furthermore, we interpret all objects as symbols with different encodings and have integrated a set of useful engines that convert these objects into the natural language domain to perform our operations.
Although our work primarily emphasizes how LLMs can assess symbolic expressions, many formal statements have already been efficiently implemented in existing symbolic engines, such as WolframAlpha. Therefore, with an API KEY from WolframAlpha, we can use their engine by using the Interface('wolframalpha'). This avoids error-prone evaluations from neuro-symbolic engines for mathematical operations. The following example demonstrates how to use WolframAlpha to compute the result of the variable x:
from symai import Interface
expression = Interface('wolframalpha')
res = expression('x^2 + 2x + 1'):Output:
x = -1To transcribe audio files, we can perform speech transcription using whisper. The following example demonstrates how to transcribe an audio file and return the text:
from symai.interfaces import Interface
speech = Interface('whisper')
res = speech('examples/audio.mp3'):Output:
I may have overslept.To extract text from images, we can perform optical character recognition (OCR) with APILayer. The following example demonstrates how to transcribe an image and return the text:
from symai.interfaces import Interface
ocr = Interface('ocr')
res = ocr('https://media-cdn.tripadvisor.com/media/photo-p/0f/da/22/3a/rechnung.jpg')The OCR engine returns a dictionary with a key all_text where the full text is stored. For more details, refer to their documentation here.
:Output:
China Restaurant\nMaixim,s\nSegeberger Chaussee 273\n22851 Norderstedt\nTelefon 040/529 16 2 ...To obtain fact-based content, we can perform search queries via SerpApi with a Google backend. The following example demonstrates how to search for a query and return the results:
from symai.interfaces import Interface
search = Interface('serpapi')
res = search('Birthday of Barack Obama'):Output:
August 4, 1961To access data from the web, we can use Selenium. The following example demonstrates how to crawl a website and return the results:
from symai.interfaces import Interface
crawler = Interface('selenium')
res = crawler(url="https://www.google.com/",
pattern="google")The pattern property can be used to verify if the document has been loaded correctly. If the pattern is not found, the crawler will timeout and return an empty result.
:Output:
GoogleKlicke hier, wenn du nach einigen Sekunden nicht automatisch weitergeleitet wirst.GmailBilderAnmelden ...To render images from text descriptions, we use DALL·E 2. The following example demonstrates how to draw a text description and return the image:
from symai.interfaces import Interface
dalle = Interface('dall_e')
res = dalle('a cat with a hat'):Output:
https://oaidalleapiprodscus.blob.core.windows.net/private/org-l6FsXDfth6Uct ...Don't worry, we would never hide an image of a cat with a hat from you. Here is the image preview and link:

To perform file operations, we use the operating system's file system. Currently, we support only PDF files and plain text files. This is an early stage, and we are working on more sophisticated file system access and remote storage. The following example demonstrates how to read a PDF file and return the text:
expr = Expression()
res = expr.open('./LICENSE'):Output:
BSD 3-Clause License\n\nCopyright (c) 2023 ...We use Pinecone to index and search for text. The following example demonstrates how to store text as an index and then retrieve the most related match:
expr = Expression()
expr.add(Symbol('Hello World!').zip())
expr.add(Symbol('I like cookies!').zip())
res = expr.get(Symbol('hello').embedding, index_name='default_index').ast()
res['matches'][0]['metadata']['text'][0]:Output:
Hello World!Here, the zip method creates a pair of strings and embedding vectors, which are then added to the index. The line with get retrieves the original source based on the vector value of hello and uses ast to cast the value to a dictionary.
You can set several optional arguments for the indexing engine. For more details, see the symai/backend/engine_pinecone.py file.
To perform text-based image few-shot classification, we use CLIP. This implementation is very experimental, and conceptually does not fully integrate the way we intend it, since the embeddings of CLIP and GPT-3 are not aligned (embeddings of the same word are not identical for both models). Aligning them remains an open problem for future research. For example, one could learn linear projections from one embedding space to the other.
The following example demonstrates how to classify the image of our generated cat from above and return the results as an array of probabilities:
clip = Interface('clip')
res = clip('https://oaidalleapiprodscus.blob.core.windows.net/private/org-l6FsXDfth6...',
['cat', 'dog', 'bird', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe']):Output:
array([[9.72840726e-01, 6.34790864e-03, 2.59368378e-03, 3.41371237e-03,
3.71197984e-03, 8.53193272e-03, 1.03346225e-04, 2.08464009e-03,
1.77942711e-04, 1.94185617e-04]], dtype=float32)You can use a locally hosted instance for the Neuro-Symbolic Engine. We build on top of:
- llama.cpp through llama-cpp-python. Please follow the
llama-cpp-pythoninstallation instructions. We make the assumption the user has experience runningllama.cppprior to using our API for local hosting. - huggingface/transformers through a custom FastAPI server.
For instance, let's suppose you want to set as a Neuro-Symbolic Engine the latest Llama 3 model. First, download the model with the HuggingFace CLI:
huggingface-cli download TheBloke/LLaMA-Pro-8B-Instruct-GGUF llama-pro-8b-instruct.Q4_K_M.gguf --local-dir .Normally, to start the server through llama.cpp you would run something that looks like this:
python -m llama_cpp.server --model ./llama-pro-8b-instruct.Q4_K_M.gguf --n_gpu_layers -1 --chat_format llama-3 --port 8000 --host localhostWith symai, simply set the NEUROSYMBOLIC_ENGINE_MODEL to llamacpp:
{
"NEUROSYMBOLIC_ENGINE_API_KEY": "",
"NEUROSYMBOLIC_ENGINE_MODEL": "llamacpp",
...
}Then, run symserver with options available for llama.cpp:
symserver --model ./llama-pro-8b-instruct.Q4_K_M.gguf --n_gpu_layers -1 --chat_format llama-3 --port 8000 --host localhostTo see all the available options llama.cpp provides, run:
symserver --helpLet's suppose we want to use dolphin-2.9.3-mistral-7B-32k from HuggingFace. First, download the model with the HuggingFace CLI:
huggingface-cli download cognitivecomputations/dolphin-2.9.3-mistral-7B-32k --local-dir ./dolphin-2.9.3-mistral-7B-32kFor the HuggingFace server, you have to set the NEUROSYMBOLIC_ENGINE_MODEL to huggingface:
{
"NEUROSYMBOLIC_ENGINE_API_KEY": "",
"NEUROSYMBOLIC_ENGINE_MODEL": "huggingface",
...
}Then, run symserver with the following options:
symserver --model ./dolphin-2.9.3-mistral-7B-32k --attn_implementation flash_attention_2To see all the available options we support for HuggingFace, run:
symserver --helpNow you are set to use the local engine.
# do some symbolic computation with the local engine
sym = Symbol('Kitties are cute!').compose()
print(sym)
# :Output:
# Kittens are known for their adorable nature and fluffy appearance, making them a favorite addition to many homes across the world. They possess a strong bond with
# their owners, providing companionship and comfort that can ease stress and anxiety. With their playful personalities, they are often seen as a symbol of happiness
# and joy, and their unique characteristics such as purring, kneading, and head butts bring warmth to our hearts. Cats also have a natural instinct to groom, which
# helps them maintain their clean and soft fur. Not only do they bring comfort and love to their owners, but they also have some practical benefits, such as reducing
# allergens, deterring pests, and even reducing stress in their surroundings. Overall, it is no surprise that pets have a long history of providing both emotional
# and physical comfort and happiness to their owners, making them a much-loved member of families around the world.If you want to replace or extend the functionality of our framework, you can do so by customizing the existing engines or creating new engines.
To create and use any other LLM as a backend you can for example change the neurosymbolic engine setting and register the new engine to the EngineRepository. The following example shows how to create a new neurosymbolic engine:
from symai.backend.base import Engine
from symai.functional import EngineRepository
# setup an engine
class MyEngine(Engine):
def id(self):
return 'neurosymbolic'
def prepare(self, argument):
# get input from the pre-processors output and use *args, **kwargs and prop from argument
# argument.prop contains all your kwargs accessible via dot `.` operation and additional meta info
# such as function signature, system relevant info etc.
prompts = argument.prop.preprocessed_input
args = argument.args
kwargs = argument.kwargs
# prepare the prompt statement as you want (take a look at the other engines like for GPT-4)
...
# assign it to prepared_input
argument.prop.prepared_input = ...
def forward(self, argument):
# get prep statement
prompt = argument.prop.prepared_input
# Your API / engine related call code here
return ...
# register your engine
EngineRepository.register('neurosymbolic', engine)Any engine is derived from the base class Engine and is then registered in the engines repository using its registry ID. The ID is for instance used in core.py decorators to address where to send the zero/few-shot statements using the class EngineRepository. You can find the EngineRepository defined in functional.py with the respective query method. Every engine has therefore three main methods you need to implement. The id, prepare and forward method. The id return the engine category. The prepare and forward methods have a signature variable called argument which carries all necessary pipeline relevant data. For instance, the output of the argument.prop.preprocessed_input contains the pre-processed output of the PreProcessor objects and is usually what you need to build and pass on to the argument.prop.prepared_input, which is then used in the forward call.
If you don't want to re-write the entire engine code but overwrite the existing prompt prepare logic, you can do so by subclassing the existing engine and overriding the prepare method.
Here is an example of how to initialize your own engine. We will subclass the existing GPTXCompletionEngine and override the prepare method. This method is called before the neural computation and can be used to modify the input prompt's parameters that will be passed in for execution. In this example, we will replace the prompt with dummy text for illustration purposes:
from symai.backend.engines.neurosymbolic.engine_gptX_completion import GPTXCompletionEngine
from symai.functional import EngineRepository
class DummyEngine(GPTXCompletionEngine):
def prepare(self, argument):
argument.prop.prepared_input = ['Go wild and generate something!']
custom_engine = DummyEngine()
sym = Symbol()
EngineRepository.register('neurosymbolic', custom_engine)
res = sym.compose()To configure an engine, we can forward commands through Expression objects by using the command method. The command method passes on configurations (as **kwargs) to the engines and change functionalities or parameters. The functionalities depend on the respective engine.
In this example, we will enable verbose mode, where the engine will print out the methods it is executing and the parameters it is using. This is useful for debugging purposes:
sym = Symbol('Hello World!')
Expression.command(engines=['neurosymbolic'], verbose=True)
res = sym.translate('German'):Output:
<symai.backend.engines.engine_gptX_completion.GPTXCompletionEngine object at 0, <function Symbol.translate.<locals>._func at 0x7fd68ba04820>, {'instance': <class 'symai.symbol.S ['\n\nHallo Welt!']Here is the list of names of the engines that are currently supported:
neurosymbolic- GPT-3, ChatGPT, GPT-4symbolic- WolframAlphaocr- Optical Character Recognitiontext_vision- CLIPtext-to-speech- TTS-1 OpenAIspeech-to-text- Whisperembedding- OpenAI Embeddings API (ada-002)userinput- User Command Line Inputserpapi- SerpApi (Google search)crawler- Seleniumexecute- Python Interpreterindex- Pineconeopen- File Systemoutput- Output Callbacks (e.g., for printing to console or storage)imagerendering- DALL·E 2
Finally, if you want to create a completely new engine but still maintain our workflow, you can use the query function from symai/functional.py and pass in your engine along with all other specified objects (i.e., Prompt, PreProcessor, etc.; see also section Custom Operations).
We are constantly working to improve the framework and overcome limitations and issues. Just to name a few:
Engineering challenges:
- Our framework constantly evolves and receives bug fixes. However, we advise caution when considering it for production use cases. For example, the Stream class only estimates the prompt size by approximation, which can fail. One can also create more sophisticated prompt hierarchies and dynamically adjust the global context based on a state-based approach. This would allow for consistent predictions even for long text streams.
- Operations need further improvements, such as verification for biases, fairness, robustness, etc.
- The code may not be complete and is not yet optimized for speed and memory usage. It utilizes API-based LLMs due to limitations in computing resources.
- Code coverage is not yet complete, and we are still working on the documentation.
- Integrate with a more diverse set of models from Hugging Face or other platforms.
- Currently, we have not accounted for multi-threading and multi-processing.
Research challenges:
- To reliably use our framework, one needs to further explore how to fine-tune LLMs to specifically solve many of the proposed operations in a more robust and efficient manner.
- The experimental integration of CLIP aims to align image and text embeddings. Enabling decision-making of LLMs based on observations and performing symbolic operations on objects in images or videos would be a significant leap forward. This integration would work well with reinforcement learning approaches and enable us to control policies systematically (see also GATO). Therefore, we need to train large multi-modal variants with image/video data and text data, describing scenes in high detail to obtain neuro-symbolic computation engines that can perform semantic operations similar to
move-towards-tree,open-door, etc. - Generalist LLMs are still highly over-parameterized, and hardware has not yet caught up to hosting these models on everyday machines. This limitation constrains the applicability of our approach not only on small data streams but also creates high latencies, reducing the amount of complexity and expressiveness we can achieve with our expressions.
We are continually working on enhancing the framework and are receptive to any suggestions, feedback, or comments. Meanwhile, we have identified several areas for potential future developments:
- Meta-learning semantic concepts on top of neuro-symbolic expressions
- Self-evolving and self-healing API
- Integration of our neuro-symbolic framework with reinforcement learning
We believe that LLMs, as neuro-symbolic computation engines, enable a new class of applications, complete with tools and APIs that can perform self-analysis and self-repair. We eagerly anticipate the future developments this area will bring and are looking forward to receiving your feedback and contributions.
We have provided a neuro-symbolic perspective on LLMs and demonstrated their potential as a central component for many multi-modal operations. We offered a technical report on utilizing our framework and briefly discussed the capabilities and prospects of these models for integration with modern software development.
This project draws inspiration from the following works, among others:
- Newell and Simon's Logic Theorist: Historical Background and Impact on Cognitive Modeling
- Search and Reasoning in Problem Solving
- The Algebraic Theory of Context-Free Languages
- Neural Networks and the Chomsky Hierarchy
- Binding Language Models in Symbolic Languages
- Tracr: Compiled Transformers as a Laboratory for Interpretability
- How can computers get common sense?
- Artificial Intelligence: A Modern Approach
- SymPy: symbolic computing in Python
- Neuro-symbolic programming
- Fuzzy Sets
- An early approach toward graded identity and graded membership in set theory
- From Statistical to Causal Learning
- Language Models are Few-Shot Learners
- Deep reinforcement learning from human preferences
- Aligning Language Models to Follow Instructions
- Chain of Thought Prompting Elicits Reasoning in Large Language Models
- Measuring and Narrowing the Compositionality Gap in Language Models
- Large Language Models are Zero-Shot Reasoners
- Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
- ReAct: Synergizing Reasoning and Acting in Language Models
- Understanding Stereotypes in Language Models: Towards Robust Measurement and Zero-Shot Debiasing
- Connectionism and Cognitive Architecture: A Critical Analysis
- Unit Testing for Concepts in Neural Networks
- Teaching Algorithmic Reasoning via In-context Learning
- PromptChainer: Chaining Large Language Model Prompts through Visual Programming
- Prompting Is Programming: A Query Language For Large Language Models
- Self-Instruct: Aligning Language Model with Self Generated Instructions
- REALM: Retrieval-Augmented Language Model Pre-Training
- Wolfram|Alpha as the Way to Bring Computational Knowledge Superpowers to ChatGPT
- Build a GitHub support bot with GPT3, LangChain, and Python
Here is a brief list contrasting our approach with other frameworks:
- We focus on cognitive science and cognitive architectures research. We believe that the current state of the art in LLMs is not yet ready for general-purpose tasks. So, we concentrate on advances in concept learning, reasoning, and flow control of the generative process.
- We consider LLMs as one type of neuro-symbolic computation engine, which could take various shapes or forms, such as knowledge graphs, rule-based systems, etc. Hence, our approach is not necessarily limited to Transformers or LLMs.
- We aim to advance the development of programming languages and new programming paradigms, along with their programming stack, including neuro-symbolic design patterns that integrate with operators, inheritance, polymorphism, compositionality, etc. Classical object-oriented and compositional design patterns have been well-studied in the literature, but we offer a novel perspective on how LLMs integrate and augment fuzzy logic and neuro-symbolic computation.
- Our proposed prompt design helps combine object-oriented paradigms with machine learning models. We believe that prompt misalignments in their current form will be alleviated with further advances in Reinforcement Learning from Human Feedback and other value alignment methods. As a result, these approaches will address the need for prompt engineering or the ability to prompt hack statements, leading to much shorter zero- or few-shot examples (at least for small enough tasks). We envision the power of a divide-and-conquer approach by performing basic operations and recombining them to tackle complex tasks.
- We view operators/methods as being able to move along a spectrum between prompting and fine-tuning, based on task-specific requirements and data availability. We believe this approach is more general compared to prompting frameworks.
- We propose a general method for handling large context sizes and transforming a data stream problem into a search problem, related to reasoning as a search problem in Search and Reasoning in Problem Solving.
We hope that our work can be seen as complementary and offer a future outlook on how we would like to use machine learning models as an integral part of programming languages and their entire computational stack.
We have a long list of acknowledgements. Special thanks go to our colleagues and friends at the Institute for Machine Learning at Johannes Kepler University (JKU), Linz for their exceptional support and feedback. We are also grateful to the AI Austria RL Community for supporting this project. Additionally, we appreciate all contributors to this project, regardless of whether they provided feedback, bug reports, code, or simply used the framework. Your support is highly valued.
Finally, we would like to thank the open-source community for making their APIs and tools publicly available, including (but not limited to) PyTorch, Hugging Face, OpenAI, GitHub, Microsoft Research, and many others.
Special thanks are owed to Kajetan Schweighofer, Markus Hofmarcher, Thomas Natschläger, and Sepp Hochreiter.
If you wish to contribute to this project, please read the CONTRIBUTING.md file for details on our code of conduct, as well as the process for submitting pull requests. Any contributions are greatly appreciated.
@software{Dinu_SymbolicAI_2022,
author = {Dinu, Marius-Constantin},
editor = {Leoveanu-Condrei, Claudiu},
title = {{SymbolicAI: A Neuro-Symbolic Perspective on Large Language Models (LLMs)}},
url = {https://github.com/ExtensityAI/symbolicai},
month = {11},
year = {2022}
}This project is licensed under the BSD-3-Clause License - see the LICENSE file for details.
If you appreciate this project, please leave a star ⭐️ and share it with friends and colleagues. To support the ongoing development of this project even further, consider donating. Thank you!
We are also seeking contributors or investors to help grow and support this project. If you are interested, please reach out to us.
Feel free to contact us with any questions about this project via email, through our website, or find us on Discord:
To contact me directly, you can find me on LinkedIn, Twitter, or at my personal website.