![]()
Building applications with LLMs at its core through our Symbolic API leverages the power of classical and differentiable programming in Python.
Read further documentation here.






Conceptually, SymbolicAI is a framework that uses machine learning - and specifically LLMs - at its core, and composes operations based on task-specific prompting. We adopt a divide and conquer approach to decompose a complex problem into smaller problems. Therefore, each operation solves a simple task. By re-combining these operations we can solve the complex problem. Furthermore, our design principles allow us to transition between differentiable and classical programming, and to leverage the power of both worlds.
- SymbolicAI
- A Neuro-Symbolic Perspective on Large Language Models (LLMs)
- Abstract
- 📖 Table of Contents
- 🔧 Get Started
- 🦖 Apps
- 🤷♂️ Why SymbolicAI?
- Tell me some more fun facts!
- 😶🌫️ How does it work?
- 😷 Operations
- Prompt Design
- 😑 Expressions
- ❌ Error Handling
- 🕷️ Interpretability, Testing & Debugging
▶️ Play around with our API- 📈 Interface for Query and Response Inspection
- 🤖 Engines
- ⚡Limitations
- 🥠 Future Work
- Conclusion
- 👥 References, Related Work & Credits
pip install symbolicaiOne can run our framework in two ways:
- using local engines (
experimental) that are run on your local machine (see Local Neuro-Symbolic Engine section), or - using engines powered by external APIs, i.e. using OpenAI's API (see API Keys).
Before the first run, define exports for the required API keys to enable the respective engines. This will register the keys in the internally for subsequent runs. By default SymbolicAI currently uses OpenAI's neural engines, i.e. GPT-3 Davinci-003, DALL·E 2 and Embedding Ada-002, for the neuro-symbolic computations, image generation and embeddings computation respectively. However, these modules can easily be replaced with open-source alternatives. Examples are
- OPT or Bloom for neuro-symbolic computations,
- Craiyon for image generation,
- and any BERT variants for semantic embedding computations.
To set the OpenAI API Keys use the following command:
# Linux / MacOS
export OPENAI_API_KEY="<OPENAI_API_KEY>"
# Windows (PowerShell)
$Env:OPENAI_API_KEY="<OPENAI_API_KEY>"
# Jupyter Notebooks (important: do not use quotes)
%env OPENAI_API_KEY=<OPENAI_API_KEY>To get started import our library by using:
import symai as aiOverall, the following engines are currently supported:
- Neuro-Symbolic Engine: OpenAI's LLMs (GPT-3)
- Embedding Engine: OpenAI's Embedding API
- [Optional] Symbolic Engine: WolframAlpha
- [Optional] Search Engine: SerpApi
- [Optional] OCR Engine: APILayer
- [Optional] SpeechToText Engine: OpenAI's Whisper
- [Optional] WebCrawler Engine: Selenium
- [Optional] Image Rendering Engine: DALL·E 2
- [Optional] Indexing Engine: Pinecone
- [Optional] CLIP Engine: 🤗 Hugging Face (experimental image and text embeddings)
SymbolicAI uses multiple engines to process text, speech and images. We also include search engine access to retrieve information from the web. To use all of them, you will need to install also the following dependencies or assign the API keys to the respective engines.
If you want to use the WolframAlpha Engine, Search Engine or OCR Engine you will need to export the following API keys:
# Linux / MacOS
export SYMBOLIC_ENGINE_API_KEY="<WOLFRAMALPHA_API_KEY>"
export SEARCH_ENGINE_API_KEY="<SERP_API_KEY>"
export OCR_ENGINE_API_KEY="<APILAYER_API_KEY>"
export INDEXING_ENGINE_API_KEY="<PINECONE_API_KEY>"
# Windows (PowerShell)
$Env:SYMBOLIC_ENGINE_API_KEY="<WOLFRAMALPHA_API_KEY>"
$Env:SEARCH_ENGINE_API_KEY="<SERP_API_KEY>"
$Env:OCR_ENGINE_API_KEY="<APILAYER_API_KEY>"
$Env:INDEXING_ENGINE_API_KEY="<PINECONE_API_KEY>"To use them, you will also need to install the following dependencies:
- SpeechToText Engine:
ffmpegfor audio processing (based on OpenAI's whisper)
# Linux
sudo apt update && sudo apt install ffmpeg
# MacOS
brew install ffmpeg
# Windows
choco install ffmpeg[Note] Additionally, you need to install the newest version directly from their repository, since the version available via pip is outdated:
pip install git+https://github.com/openai/whisper.git- WebCrawler Engine: For
selenium, download the corresponding driver version by setting theSELENIUM_CHROME_DRIVER_VERSIONenvironment variable. Currently we use Chrome as the default browser. This means that the Chrome version major number must match the ChromeDriver version. All versions are available here. For example, if you use chrome version109.0.5414.74, you can set any109.x.x.xversion for thechromedriver. In this case the109.0.5414.74is available on the selenium page, therefore the environment variable is set to it:
# Linux / MacOS
export SELENIUM_CHROME_DRIVER_VERSION="109.0.5414.74"
# Windows (PowerShell)
$Env:SELENIUM_CHROME_DRIVER_VERSION="109.0.5414.74"Alternatively, you can specify in your project path a symai.config.json file with all the engine properties. This will replace the environment variables. See the following configuration file as an example:
{
"NEUROSYMBOLIC_ENGINE_API_KEY": "<OPENAI_API_KEY>",
"NEUROSYMBOLIC_ENGINE_MODEL": "text-davinci-003",
"SYMBOLIC_ENGINE_API_KEY": "<WOLFRAMALPHA_API_KEY>",
"EMBEDDING_ENGINE_API_KEY": "<OPENAI_API_KEY>",
"EMBEDDING_ENGINE_MODEL": "text-embedding-ada-002",
"IMAGERENDERING_ENGINE_API_KEY": "<OPENAI_API_KEY>",
"VISION_ENGINE_MODEL": "openai/clip-vit-base-patch32",
"SEARCH_ENGINE_API_KEY": "<SERP_API_KEY>",
"SEARCH_ENGINE_MODEL": "google",
"OCR_ENGINE_API_KEY": "<APILAYER_API_KEY>",
"SPEECH_ENGINE_MODEL": "base",
"SELENIUM_CHROME_DRIVER_VERSION": "110.0.5481.30",
"INDEXING_ENGINE_API_KEY": "<PINECONE_API_KEY>",
"INDEXING_ENGINE_ENVIRONMENT": "us-west1-gcp"
}Over the course of th next weeks, we will expand our experimental demo apps and provide a set of useful tools that showcase how to interact with our framework. These apps are made available by calling the sym+<shortcut-name-of-app> command in your terminal or PowerShell.
You can start a basic shell command support tool that translates natural language commands into shell commands. To start the shell command tool, simply run:
symsh "<your-query>"You can also use the --help flag to get more information about the tool and available arguments.
symsh --helpHere is an example of how to use the tool:
$> symsh "PowerShell edit registiry entry"
# :Output:
# Set-ItemProperty -Path <path> -Name <name> -Value <value>
$> symsh "Set-ItemProperty -Path <path> -Name <name> -Value <value>" --add "path='/Users/myuser' name=Demo value=SymbolicAI"
# :Output:
# Set-ItemProperty -Path '/Users/myuser' -Name Demo -Value SymbolicAI
$> symsh "Set-ItemProperty -Path '/Users/myuser' -Name Demo -Value SymbolicAI" --del "string quotes"
# :Output:
# Set-ItemProperty -Path /Users/myuser -Name Demo -Value SymbolicAI
$> symsh "Set-ItemProperty -Path '/Users/myuser' -Name Demo -Value SymbolicAI" --convert "linux"
# :Output:
# export Demo="SymbolicAI"You can start a basic conversation with Symbia. Symbia is a chatbot that uses SymbolicAI to detect the content of your request and switch between different contextual modes to answer your questions. These mode include search engines, speech engines and more. To start the chatbot, simply run:
symchatThis will start now a chatbot interface:
Symbia: Hi there! I'm Symbia, your virtual assistant. How may I help you?
$> You can exit the conversation by either typing exit, quit or pressing Ctrl+C.
We compiled a few examples to show how to use our Symbolic API. You can find them in the notebooks folder.
- Basics: See our basics notebook to get familiar with our API structure (notebooks/Basics.ipynb)
- Queries: See our query manipulation notebook for contextualized operations (notebooks/Queries.ipynb)
- News & Docs Generation: See our news and documentation generation notebook for stream processing (notebooks/News.ipynb)
- ChatBot: See how to implement a custom chatbot based on semantic narrations (notebooks/ChatBot.ipynb)
You can solve many more problems with our Symbolic API. We are looking forward to see what you will build with it. Keep us posted on our shared community space on Discord: AI Is All You Need / SymbolicAI.
We are listing all your cool demos and tools that you build with our framework. If you want to add your project just PM on Twitter at @SymbolicAPI or via Discord.
SymbolicAI tries to close the gap between classical programming or Software 1.0 and modern data-driven programming (aka Software 2.0). It is a framework that allows to build software applications, which are able to utilize the power of large language models (LLMs) wtih composability and inheritance - two powerful concepts from the object-oriented classical programming paradigm.
This allows to move along the spectrum between the classical programming realm and data-driven programming realm as illustrated in the following figure:
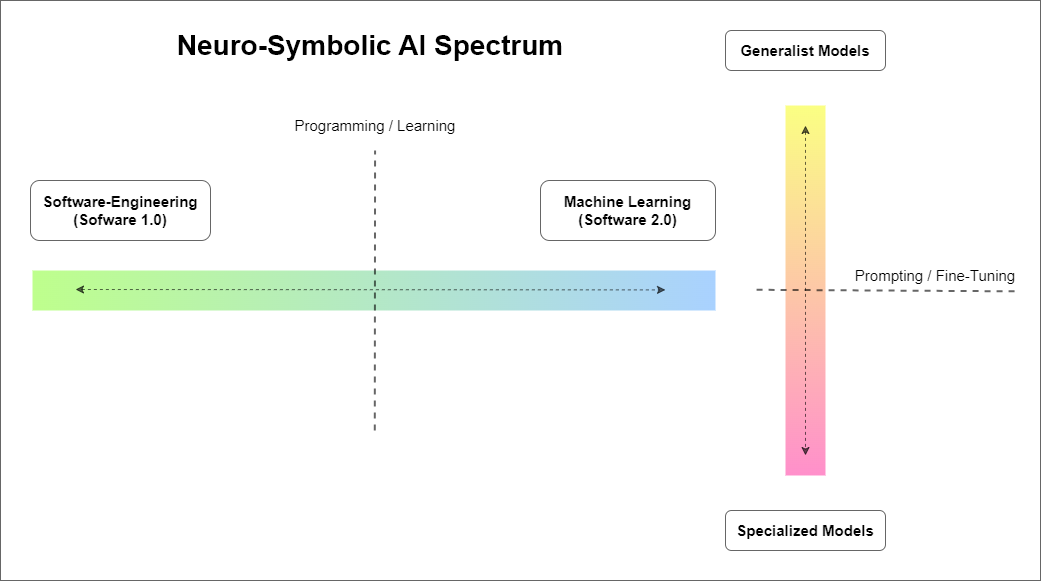
As briefly mentioned, we adopt a divide and conquer approach to decompose a complex problem into smaller problems. We then use the expressiveness and flexibility of LLMs to evaluate these sub-problems and by re-combining these operations we can solve the complex problem.
In this turn, and with enough data, we can gradually transition between general purpose LLMs with zero and few-shot learning capabilities, and specialized fine-tuned models to solve specific problems (see above). This means that each operations could be designed to use a model with fine-tuned task-specific behavior.

In its essence, SymbolicAI was inspired by the neuro-symbolic programming paradigm.
Neuro-symbolic programming is a paradigm for artificial intelligence and cognitive computing that combines the strengths of both deep neural networks and symbolic reasoning.
Deep neural networks are a type of machine learning algorithms that are inspired by the structure and function of biological neural networks. They are particularly good at tasks such as image recognition, natural language processing etc. However, they are not as good at tasks that require explicit reasoning, such as long-term planning, problem solving, and understanding causal relationships.
Symbolic reasoning, on the other hand uses formal languages and logical rules to represent knowledge and perform tasks such as planning, problem solving, and understanding causal relationships. Symbolic reasoning systems are good at tasks that require explicit reasoning, but are not as good at tasks that require pattern recognition or generalization, such as image recognition or natural language processing.
Neuro-symbolic programming aims to combine the strengths of both neural networks and symbolic reasoning to create AI systems that can perform a wide range of tasks. One way this is done is by using neural networks to extract information from data and then using symbolic reasoning to make inferences and decisions based on that information. Another way is to use symbolic reasoning to guide the generative process of neural networks and make them more interpretable.
Embedded accelerators for LLMs will, in our opinion, be ubiquitous in future computation platforms, such as wearables, smartphones, tablets or notebooks. They will contain models similar to GPT-3, ChatGPT, OPT or Bloom.
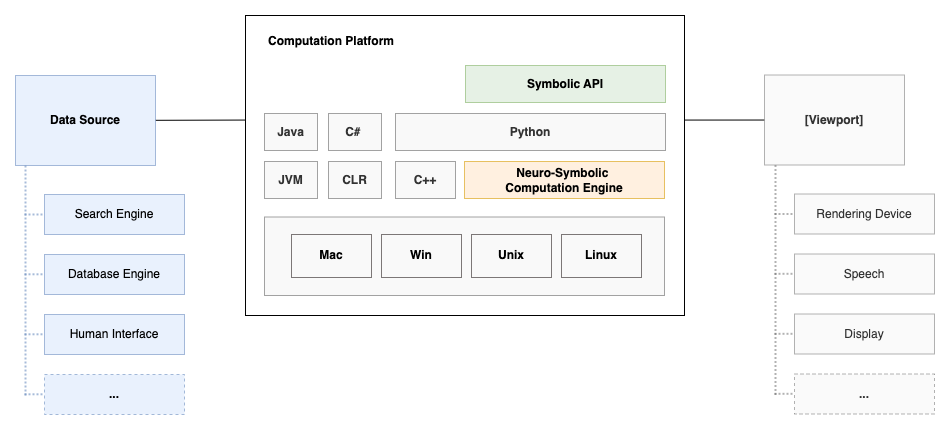
These LLMs will be able to perform a wide range of computations, such as natural language understanding or decision making. Furthermore, neuro-symbolic computation engines will be able to learn concepts how to tackle unseen tasks and solve complex problems by querying various data sources for solutions and executing logical statements on top. In this turn, to ensure the generated content is in alignment with our goals, we need to develop ways to instruct, steer and control the generative processes of machine learning models. Therefore, our approach is an attempt to enable active and transparent flow control of these generative processes.
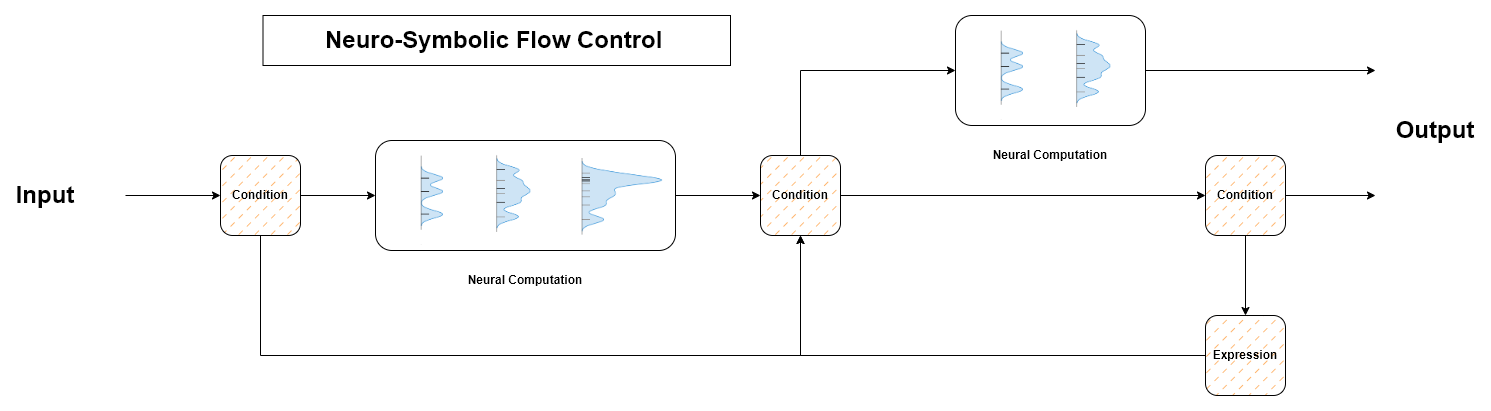
As shown in the figure above, one can think of this generative process as shifting a probability mass of an input stream of data towards an output stream of data, in a contextualized manner. With properly designed conditions and expressions, one can also validate and steer the behavior towards a desired outcome, or repeat expressions that failed to fulfil our requirements. Our approach is to define a set of fuzzy operations that manipulate the data stream and conditions the LLMs to align with our goals. In essence, we consider all data objects, such as strings, letters, integers, arrays, etc. as symbols and we see natural language as the main interface to interact with. See the following figure:
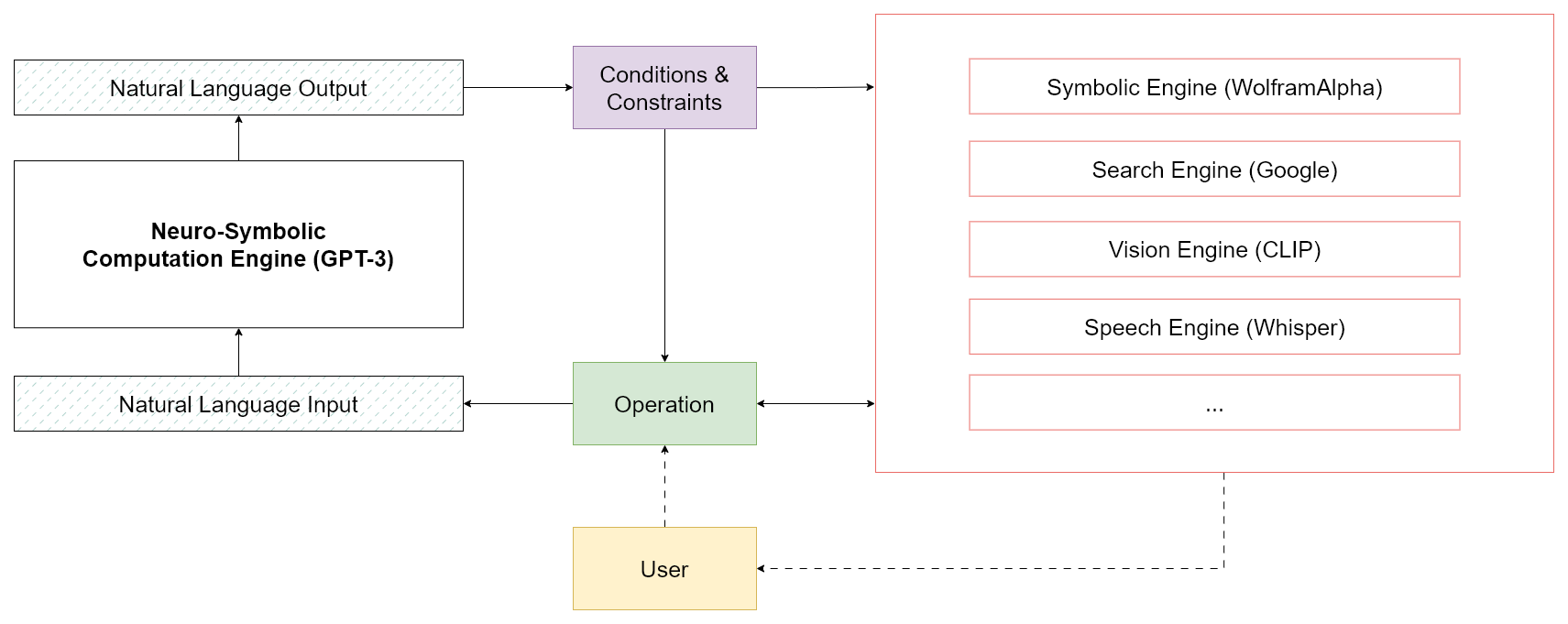
We show that as long as we can express our goals in natural language, we can use the power of LLMs for neuro-symbolic computations. In this turn, we create operations that manipulate these symbols to generate new symbols from them. Each symbol can be interpreted as a statement. Multiple statements can be combined to form a logical expression.
Therefore, by chaining statements together we can build causal relationships and computations, instead of relying only on inductive approaches. Consequently, the outlook towards an updated computational stack resembles a neuro-symbolic computation engine at its core and, in combination with established frameworks, enables new applications.
We now show how we define our Symbolic API, which is based on object-oriented and compositional design patterns. The Symbol class is the base class for all functional operations, which we refer to as a terminal symbol in the context of symbolic programming (fully resolved expressions). The Symbol class holds helpful operations that can be interpreted as expressions to manipulate its content and evaluate to new Symbols.
Let us now define a Symbol and perform some basic manipulations. We start with a translation operation:
sym = ai.Symbol("Welcome to our tutorial.")
sym.translate('German'):[Output]:
<class 'symai.expressions.Symbol'>(value=Willkommen zu unserem Tutorial.)Our API can also perform basic data-agnostic operations to filter, rank or extract patterns. For example, we can rank a list of numbers:
sym = ai.Symbol(numpy.array([1, 2, 3, 4, 5, 6, 7]))
res = sym.rank(measure='numerical', order='descending'):[Output]:
<class 'symai.expressions.Symbol'>(value=['7', '6', '5', '4', '3', '2', '1'])As an inspiration, we relate to an approach demonstrated by word2vec.
Word2Vec generates dense vector representations of words by training a shallow neural network to predict a word given its neighbors in a text corpus. The resulting vectors are then used in a wide range of natural language processing applications, such as sentiment analysis, text classification, and clustering.
Below we can see an example how one can perform operations on the word embeddings (colored boxes). The words are tokenized and mapped to a vector space, where we can perform semantic operations via vector arithmetics.
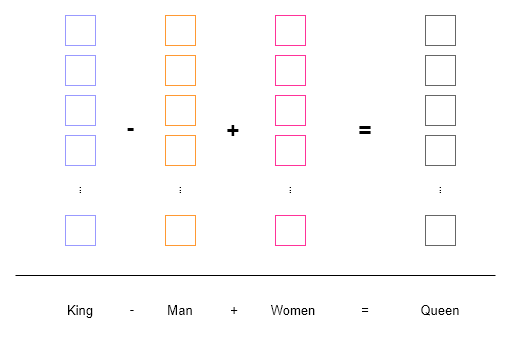
Similar to word2vec we intend to perform contextualized operations on different symbols, however, instead of operating in the vector space, we operate in the natural language domain. This gives us the ability to perform arithmetics on words, sentences, paragraphs, etc. and verify the results in a human readable format.
The following examples show how to evaluate such an expression via a string representation:
Symbol('King - Man + Women').expression():[Output]:
<class 'symai.expressions.Symbol'>(value=Queen)We can also subtract sentences from each other, where our operations condition the neural computation engine to evaluate the Symbols by best effort. In the following example, it determines that the word enemy is present in the sentence, therefore deletes it and replaces it with the word friend (which is added):
res = ai.Symbol('Hello my enemy') - 'enemy' + 'friend':[Output]:
<class 'symai.expressions.Symbol'>(value=Hello my friend)What we also see is that the API performs dynamic casting, when data types are combined with a Symbol object. If an overloaded operation of the Symbol class is used, the Symbol class can automatically cast the second object to a Symbol. This is a convenient modality to perform operations between Symbolobjects and other types of data, such as strings, integers, floats, lists, etc. without bloating the syntax.
In this example we are fuzzily comparing two number objects, where the Symbol variant is only an approximation of numpy.pi. Given the context of the fuzzy equals == operation, this comparison still succeeds and returns True.
sym = ai.Symbol('3.1415...')
sym == numpy.pi:[Output]:
TrueOur framework was built with the intention to enable reasoning capabilities on top of statistical inference of LLMs. Therefore, we can also perform deductive reasoning operations with our Symbol objects. For example, we can define a set of operations with rules that define the causal relationship between two symbols. The following example shows how the & is used to compute the logical implication of two symbols.
res = Symbol('The horn only sounds on Sundays.') & Symbol('I hear the horn.'):[Output]:
<class 'symai.expressions.Symbol'>(value=It is Sunday.)The current &-operation overloads the and logical operator and sends few-shot prompts how to evaluate the statement to the neural computation engine. However, we can define more sophisticated logical operators for and, or and xor via formal proof statements and use the neural engines to parse data structures prior to our expression evaluation. Therefore, one can also define custom operations to perform more complex and robust logical operations, including constraints to validate the outcomes and ensure a desired behavior.
To provide a more complete picture, we also sketch more comprehensive causal examples below, where one tries to obtain logical answers, based on questions of the kind:
# 1) "A line parallel to y = 4x + 6 passes through (5, 10). What is the y-coordinate of the point where this line crosses the y-axis?"
# 2) "Bob has two sons, John and Jay. Jay has one brother and father. The father has two sons. Jay's brother has a brother and a father. Who is Jay's brother."
# 3) "is 1000 bigger than 1063.472?"To give an rough idea of how we would approach this with our framework is by, first, using a chain of operations to detect the neural engine that is best suited to handle this task, and second, prepare the input for the respective engine. Let's see an example:
val = "<one of the examples above>"
# First define a class that inherits from the Expression class
class ComplexExpression(Expression): # more to the Expression class in later sections
# write a method that returns the causal evaluation
def causal_expression(self):
pass # see below for implementation
# instantiate an object of the class
expr = ComplexExpression(val)
# set WolframAlpha as the main expression engine to use
expr.command(engines=['symbolic'], expression_engine='wolframalpha')
# evaluate the expression
res = expr.causal_expression()Now, the implementation of causal_expression could in principle look like this:
def causal_expression(self):
# very which case to use `self.value` contains the input
if self.isinstanceof('mathematics'):
# get the mathematical formula
formula = self.extract('mathematical formula')
# verify which problem type we have
if formula.isinstanceof('linear function'):
# prepare for wolframalpha
question = self.extract('question sentence')
req = question.extract('what is requested?')
x = self.extract('coordinate point (.,.)') # get coordinate point / could also ask for other points
query = formula @ f', point x = {x}' @ f', solve {req}' # concatenate to the question and formula
res = query.expression(query) # send prepared query to wolframalpha
elif formula.isinstanceof('number comparison'):
res = formula.expression() # send directly to wolframalpha
... # more cases
elif self.isinstanceof('linguistic problem'):
sentences = self / '.' # first split into sentences
graph = {} # define graph
for s in sentences:
sym = Symbol(s)
relations = sym.extract('connected entities (e.g. A has three B => A | A: three B)') / '|' # and split by pipe
for r in relations:
... # add relations and populate graph => alternatively, read also about CycleGT
... # more cases
return resThe above example shows how we can use the causal_expression expression method to step-wise iterate and extract information which we can then either manually or using external solvers resolve.
Attention: We hint the reader that this is a very rough sketch and that the implementation of the causal_expression method would need much more engineering effort. Furthermore, the currently used GPT-3 LLM backend often fails to extract the correct information or resolve the right comparison. However, we strongly believe in the advances of the field and that this will change in the future, specifically with fine-tuned models like ChatGPT with Reinforcement Learning from Human Feedback (RLHF).
Lastly, it is also noteworthy that given enough data, we could fine-tune methods that extract information or build our knowledge graph from natural language. This would enable us to perform more complex reasoning tasks, such as the ones mentioned above. Therefore, we also point the reader to recent publications for translating Text-to-Graphs. This means that in the attempt to answer the query, we can simply traverse the graph and extract the information we need.
In the next section, we will explore operations.
Operations are at the core of our framework. They are the building blocks of our API and are used to define the behavior of our symbols. We can think of operations as contextualized functions that take in a Symbol object, send it to the neuro-symbolic engine for evaluation, and return one or multiple new objects (mainly new symbols; but not necessarily limited to that). Another fundamental property is polymorphism, which means that operations can be applied to different types of data, such as strings, integers, floats, lists, etc. with different behaviors, depending on the object instance.
The way we execute operations is by using the Symbol object value attribute containing the original data type that is then sent as a string representations to the engines to perform the operations. Therefore all values are casted to a string representation. This also means, that for custom objects one needs to define a proper __str__ method to cast the object to a string representation and ensure preservation of the semantics of that object.
Lastly, we need to talk about inheritance. Our API is built on top of the Symbol class, which is the base class of all operations. This means that all operations are inherited from the Symbol class. This provides a convenient modality to add new custom operations by sub-classing Symbol, yet, ensuring to always have a set of base operations at our disposal without bloating the syntax or re-implementing many existing functionalities. This also means that we can define contextualized operations with individual constraints, prompt designs and therefore behaviors by simply sub-classing the Symbol class and overriding the corresponding method. However, we recommend sub-classing the Expression class as we will see later, it adds additional functionalities.
Here is an example of how to define a custom == operation by overriding the __eq__ method and providing a custom prompt object with a list of examples:
class Demo(ai.Symbol):
def __eq__(self, other) -> bool:
@ai.equals(examples=ai.Prompt([
"1 == 'ONE' =>True",
"'six' == 7 =>False",
"'Acht' == 'eight' =>True",
...
])
)
def _func(_, other) -> bool:
return False # default behavior on failure
return _func(self, other)As shown in the above example, this is also the way we implemented the basic operations in Symbol, by defining local functions that are then decorated with the respective operation decorator from the symai/core.py file. The symai/core.py is a collection of pre-defined operation decorators that we can quickly apply to any function. The reason why we use locally defined functions instead of directly decorating the main methods, is that we do not necessarily want that all our operations are sent to the neural engine and could implement a default behavior. Another reason is that we want to cast return types of the operation outcome to symbols or other derived classes thereof. This is done by using the self._sym_return_type(...) method and can give contextualized behavior based on the defined return type. See more details in the actual Symbol class.
In the next section, we will show that almost all operations in symai/core.py are derived from the more generic few_shot decorator.
One can also define customized operations. For example, let us define a custom operation to generate a random integer between 0 and 10:
class Demo(ai.Symbol):
def __init__(self, value = '') -> None:
super().__init__(value)
@ai.zero_shot(prompt="Generate a random integer between 0 and 10.",
constraints=[
lambda x: x >= 0,
lambda x: x <= 10
])
def get_random_int(self) -> int:
passAs we show, the Symbolic API uses Python Decorators to define operations. The @ai.zero_shot decorator is used to define a custom operation that does not require any demonstration examples, since the prompt is expressive enough. In the shown example, the zero_shot decorator takes in two arguments: prompt and constraints. The former is used to define the prompt that conditions our desired operation behavior. The latter is used to define validation constraints of the computed outcome, to ensure it fulfills our expectations.
If the constraint is not fulfilled, the above implementation would reach out to the specified default implementation or default value. If no default implementation or value was found, the Symbolic API would raise an ConstraintViolationException.
We also see that in the above example the return type is defined as int. Therefore, the resulting value from the wrapped function will be of type int. This works because our implementation uses auto-casting to a user specified return data type. If the cast fails, the Symbolic API will raise a ValueError. If no return type is specified, the return type will be Any.
The @ai.few_shot decorator is the a generalized version of @ai.zero_shot and is used to define a custom operation that requires demonstration examples. To give a more complete picture, we present the function signature of the few_shot decorator:
def few_shot(prompt: str,
examples: Prompt,
constraints: List[Callable] = [],
default: Optional[object] = None,
limit: int = 1,
pre_processor: Optional[List[PreProcessor]] = None,
post_processor: Optional[List[PostProcessor]] = None,
**wrp_kwargs):The prompt and constraints attributes behavior is similar to the zero_shot decorator. The examples and limit arguments are new. The examples argument is used to define a list of demonstrations that are used to condition the neural computation engine. The limit argument is used to define the maximum number of examples that are returned, give that there are more results. The pre_processor argument takes a list of PreProcessor objects which can be used to pre-process the input before it is fed into the neural computation engine. The post_processor argument takes a list of PostProcessor objects which can be used to post-process the output before it is returned to the user. The wrp_kwargs argument is used to pass additional arguments to the wrapped method, which are also stream-lined towards the neural computation engine and other engines.
To give a more holistic picture ouf our conceptional implementation, see the following flow diagram containing the most important classes:
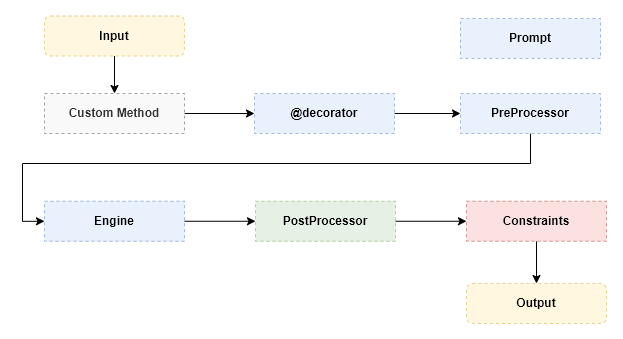
The colors indicate logical groups of data processing steps. Yellow indicates the input and output data. Blue indicates places you can customize or prepare the input of your engine. Green indicates post-processing steps of the engine response. Red indicates the application of constraints (which also includes the attempted casting of the return type signature, if specified in the decorated method). Grey indicates the custom method which defines all properties, therefore has access to all the above mentioned objects.
To conclude this section, here is an example how to write a custom Japanese name generator with our @ai.zero_shot decorator:
import symai as ai
class Demo(ai.Symbol):
@ai.few_shot(prompt="Generate Japanese names: ",
examples=ai.Prompt(
["愛子", "和花", "一郎", "和枝"]
),
limit=2,
constraints=[lambda x: len(x) > 1])
def generate_japanese_names(self) -> list:
return ['愛子', '和花'] # dummy implementationShould the neural computation engine not be able to compute the desired outcome, it will reach out to the default implementation or default value. If no default implementation or value was found, the method call will raise an exception.
The way all the above operations are performed is by using a Prompt class. The Prompt class is a container for all the information that is needed to define a specific operation. The Prompt class is also the base class for all other Prompt classes.
Here is an example how to define a Prompt to enforce the neural computation engine for comparing two values:
class CompareValues(ai.Prompt):
def __init__(self) -> ai.Prompt:
super().__init__([
"4 > 88 =>False",
"-inf < 0 =>True",
"inf > 0 =>True",
"4 > 3 =>True",
"1 < 'four' =>True",
...
])For example, when calling the <= operation on two Symbols, the neural computation engine will evaluate the symbols in the context of the CompareValues prompt.
res = ai.Symbol(1) <= ai.Symbol('one')This statement evaluates to True, since the fuzzy compare operation was conditions our engine to compare the two Symbols based on their semantic meaning.
:[Output]:
TrueIn a more general notion, depending on the context hierarchy of the expression class and used operations the semantics of the Symbol operations may vary. To better illustrate this, we show our conceptual prompt design in the following figure:
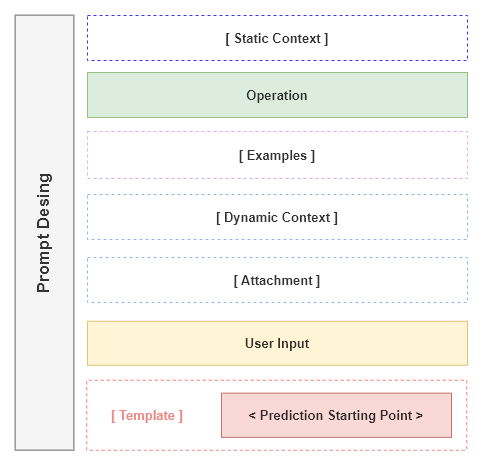
The figure shows our hierarchical prompt design as a container of all the information that is provided to the neural computation engine to define a task-specific operation. The Yellow and Green highlighted boxes indicate mandatory string placements. The dashed boxes are optional placeholders. and the Red box indicates the starting point of the model prediction.
Conceptually we consider three main prompt designs: Context-based Prompts, Operational Prompts, and Templates. The prompts can be curated either by inheritance or by composition. For example, the Static Context can be defined by inheriting from the Expression class and overriding the static_context property. An Operation and Template prompt can be created by providing an PreProcessor to modify the input data.
We will now explain each prompt concept in more details:
-
The
Context-based Prompts (Static, Dynamic and Attachment)are considered optional and can be defined in a static manner, either by sub-classing the Expression class and overriding thestatic_contextproperty, or at runtime by updating thedynamic_contextproperty or passing anattachkwargs to a method. Here is an example how to use theattachkwargs via the method signature:# creating a query to ask if an issue was resolve or not sym = Symbol("<some-community-conversation>") q = sym.query("Was the issue resolved?") # write manual condition to check if the issue was resolved if 'not resolved' in q: # do a new query but attach the previous query answer to the new query sym.query("What was the resolution?", attach=q) ... else: pass # all good
Regardless of how we set the context, our contextualized prompt defines the desired behavior of the Expression operations. For example, if we want to operate in the context of a domain-specific language, without having to override each base class method. See more details in this notebook.
-
The
Operationprompts define the behavior of an atomic operation and is therefore mandatory to express the nature of such an operation. For example, the+-operation is used to add two Symbols together and therefore the+-operation prompt explains its behavior.Examplesdefines another optional structure that provides the neural computation engine with a set of demonstrations that are used to properly condition the engine. For example, the+-operation prompt can be conditioned on how to add numbers by providing a set of demonstrations, such as1 + 1 = 2,2 + 2 = 4, etc. -
The
Templateprompts are optional and encapsulates the resulting prediction to enforce a specific format. For example, to generate HTML tags we can use a curated<html>{{placeholder}}</html>template. This template will enforce the neural computation engine to start the generation process already in the context of a HTML tags format, and not produce irrelevant descriptions about its task.
An Expression is a non-terminal symbol, which can be further evaluated. It inherits all the properties from Symbol and overrides the __call__ method to evaluate its expressions or values. From the Expression class, all other expressions are derived. The Expression class also adds additional capabilities i.e. to fetch data from URLs, search on the internet or open files. These operations are specifically separated from Symbol since they do not use the value attribute of the Symbol class.
SymbolicAI' API closely follows best practices and ideas from PyTorch, therefore, one can build complex expressions by combining multiple expressions as a computational graph. Each Expression has its own forward method, which has to be overridden. The forward method is used to define the behavior of the expression. The forward method is called by the __call__ method, which is inherited from the Expression base class. The __call__ evaluates an expression and returns the result from the implemented forward method. This design pattern is used to evaluate the expressions in a lazy manner, which means that the expression is only evaluated when the result is needed. This is a very important feature, since it allows us to chain complex expressions together. We already implemented many useful expressions, which can be imported from the symai.components file.
Other important properties that are inherited from the Symbol class are _sym_return_type and static_context. These two properties define the context in which the current Expression operates, as described in the Prompt Design section. The static_context therefore influences all operations of the current Expression sub-class. The _sym_return_type ensures that after each evaluation of an Expression, we obtain the desired return object type. This is usually implemented to return the current type, but can be set to return a different type.
Expressions can of course have more complex structures and be further sub-classed, such as shown in the example of the Sequence expression in the following figure:
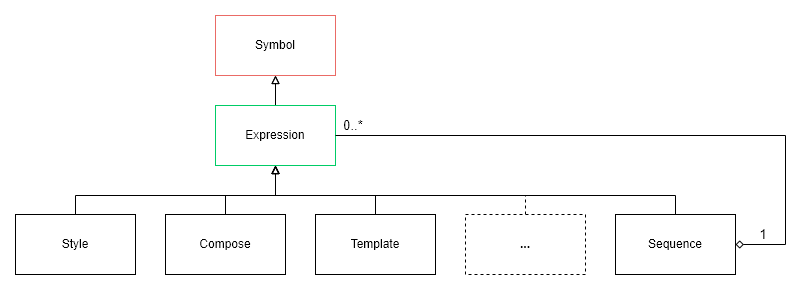
A Sequence expression can hold multiple expressions, which are evaluated at runtime.
Here is an example how to define a Sequence expression:
# first import all expressions
from symai import *
# define a sequence of expressions
Sequence(
Clean(),
Translate(),
Outline(),
Compose('Compose news:'),
)As we saw earlier, we can create contextualized prompts to define the behavior of operations on our neural engine. However, this also takes away a lot of the available context size and since e.g. the GPT-3 Davinci context length is limited to 4097 tokens, this might quickly become a problem. Luckily, we can use the Stream processing expression. This expression opens up a data stream and performs chunk-based operations on the input stream.
A Stream expression can easily be wrapped around other expressions. For example, the chunks can be processed with a Sequence expression, that allows multiple chained operations in sequential manner. Here is an example how to define such a Stream expression:
Stream(Sequence(
Clean(),
Translate(),
Outline(),
Embed()
))The shown example opens a stream, passes a Sequence object which cleans, translates, outlines and embeds the input.
Internally, the stream operation estimates the available model context size and chunks the long input text into smaller chunks, which are passed to the inner expression. The returned object type is a generator.
The issue with this approach is, that the resulting chunks are processed independently. This means there is no shared context or information among chunks. To solve this issue, we can use the Cluster expression instead, where the independent chunks are merged based on their similarity. We illustrate this in the following figure:
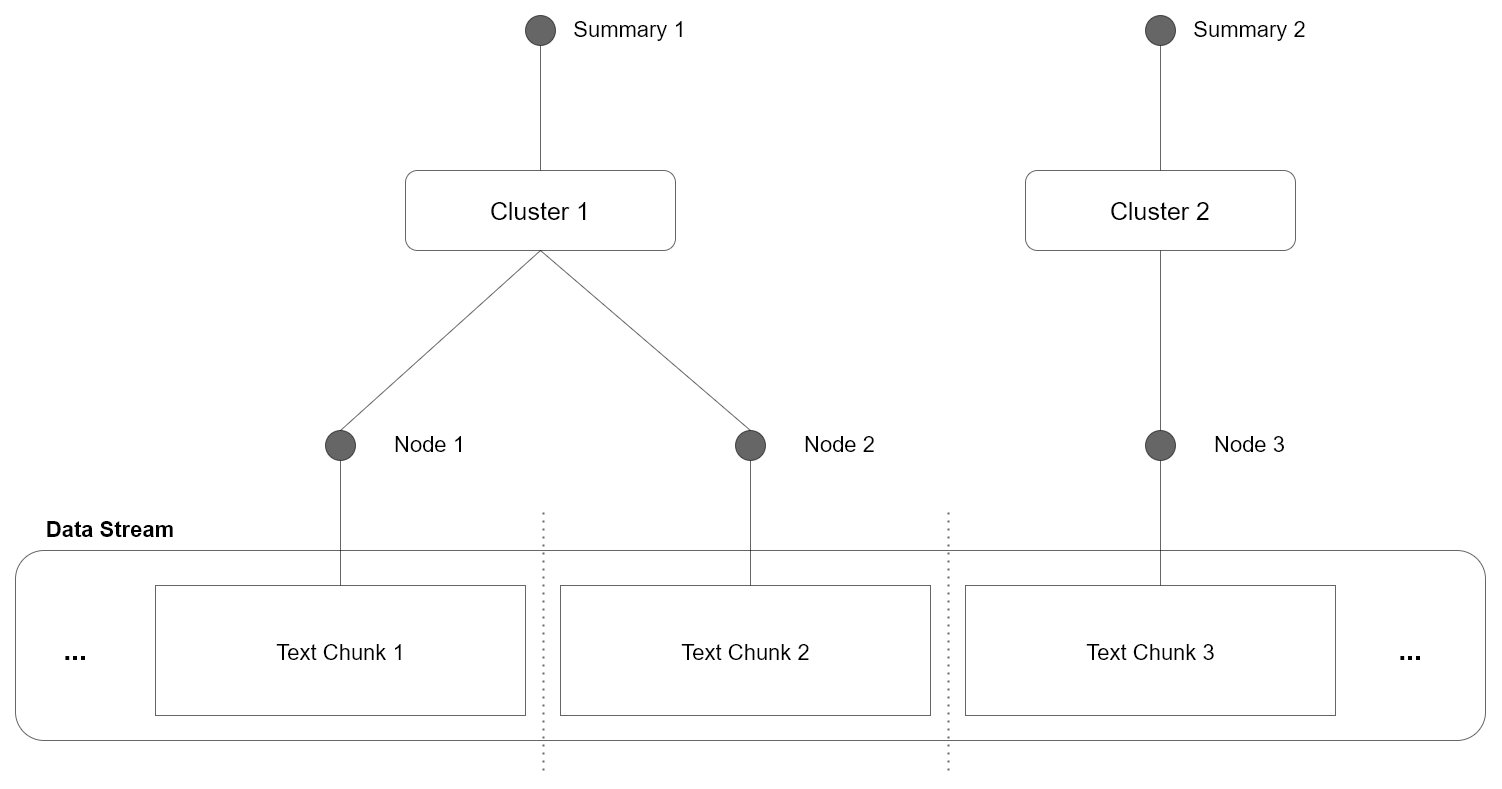
In the shown example all individual chunks are merged by clustering the information within each chunk. This gives us a way to consolidate contextually related information and merge them in a meaningful way. Furthermore, the clustered information can then be labeled by streaming through the content of each cluster and extracting the most relevant labels, providing us with interpretable node summaries.
The full example is shown below:
stream = Stream(Sequence(
Clean(),
Translate(),
Outline(),
))
sym = Symbol('<some long text>')
res = Symbol(list(stream(sym)))
expr = Cluster()
expr(res)In a next step, we could recursively repeat this process on each summary node, therefore, build a hierarchical clustering structure. Since each Node resembles a summarized sub-set of the original information we can use the summary as an index. The resulting tree can then be used to navigate and retrieve the original information, turning the large data stream problem into a search problem.
Alternatively, we could use vector-base similarity search to find similar nodes. For searching in a vector space we can use dedicated libraries such as Annoy, Faiss or Milvus.
A key idea of the SymbolicAI API is to be able to generate code. This in turn means that errors may occur, which we need to handle in a contextual manner. As a future vision, we even want our API to self extend and therefore need to be able to resolve issues automatically. To do so, we propose the Try expression, which has a fallback statements built-in and retries an execution with dedicated error analysis and correction. This expression analyses the input and the error, and conditions itself to resolve the error by manipulating the original code. If the fallback expression succeeds, the result is returned. Otherwise, this process is repeated for the number of retries specified. If the maximum number of retries is reached and the problem was not resolved, the error is raised again.
Let us assume, we have some executable code that was previously generated. However, by the nature of generative processes syntax errors may occur. By using the Execute expression, we can evaluate our generated code, which takes in a symbol and tries to execute it. Naturally, this will fail. However, in the following example the Try expression resolves this syntactic error and the receive a computed result.
expr = Try(expr=Execute())
sym = Symbol('a = int("3,")') # some code with a syntax error
res = expr(sym)The resulting output is the evaluated code, which was corrected:
:Output:
a = 3We are aware that not all errors are as simple as the shown syntactic error example, which can be resolved automatically. Many errors occur due to semantic misconceptions. Such issues require contextual information. Therefore, we are further exploring means towards more sophisticated error handling mechanism. This includes also the usage of streams and clustering to resolve errors in a more hierarchical contextual manner. It is also noteworthy that neural computations engines need to be further improved to better detect and resolve errors.
Perhaps one of the greatest benefits of using neuro-symbolic programming is, that we can get a clear understanding of how well our LLMs understand simple operations. Specifically we gain knowledge about if, and at which point they fail, enabling us to follow their StackTraces and determine the failure points. In our case, neuro-symbolic programming allows us to debug the model predictions based on dedicated unit test for simple operations. To detect conceptual misalignments we can also use a chain of neuro-symbolic operations and validate the generative process. This is of course not a perfect solution, since the verification may also be error prone, but it gives us at least a principle way to detect conceptual flaws and biases in our LLMs.
Since our premise is to divide and conquer complex problems, we can curate conceptual unit test and target very specific and tracktable sub-problems. The resulting measure, i.e. success rate of the model prediction, can then be used to evaluate their performance, and hint towards undesired flaws or biases.
This allows us to design domain-specific benchmarks and see how well general learners, such as GPT-3, adapt with certain prompts to a set of tasks.
For example, we can write a fuzzy comparison operation, that can take in digits and strings alike, and perform a semantic comparison. LLMs can then be asked to evaluate these expressions. Often times, these LLMs still fail to understand the semantic equivalence of tokens in digits vs strings and give wrong answers.
The following code snipped shows a unit test to perform semantic comparison of numbers (between digits and strings):
import unittest
from symai import *
class TestComposition(unittest.TestCase):
def test_compare(self):
res = Symbol(10) > Symbol(5)
self.assertTrue(res)
res = Symbol(1) < Symbol('five')
self.assertTrue(res)
...When creating very complex expressions, we debug them by using the Trace expression, which allows to print out the used expressions, and follow the StackTrace of the neuro-symbolic operations. Combined with the Log expression, which creates a dump of all prompts and results to a log file, we can analyze where our models potentially failed.
In the following example we create a news summary expression that crawls the given URL and streams the site content through multiple expressions. The outcome is a news website that is created based on the crawled content. The Trace expression allows to follow the StackTrace of the operations and see what operations are currently executed. If we open the outputs/engine.log file we can see the dumped traces with all the prompts and results.
# crawling the website and creating an own website based on its facts
news = News(url='https://www.cnbc.com/cybersecurity/',
pattern='cnbc',
filters=ExcludeFilter('sentences about subscriptions, licensing, newsletter'),
render=True)
expr = Log(Trace(news))
res = expr()Here is the corresponding StackTrace of the model:
The above code creates a webpage with the crawled content from the original source. See the preview below, the entire rendered webpage image here and resulting [code of webpage here](https://raw.githubusercontent.com/Xpitfire/symbolicai/main/examples/results/news.html.
{kind=link}

Launch and explore the notebook here:
There are many more examples in the examples folder and in the notebooks folder. You can also explore the test cases in the tests folder.
SymbolicAI is by design a data-driven framework. This means that we can collect data from API interactions while we provide the requested responses. For very agile, dynamic adaptations or prototyping we can integrate user desired behavior quickly into existing prompts. However, we can also log the user queries and model predictions to make them available for post-processing. Therefore, we can customize and improve the model's responses based on real-world data.
In the following example, we show how we can use an Output expression to pass a handler function and access input prompts of the model and model predictions. These, can be used for data collection and later fine-tuning stages. The handler function provides a dictionary and offers keys for input and output values. The content can then be sent to a data pipeline for further processing.
sym = Symbol('Hello World!')
def handler(res):
input_ = res['input']
output = res['output']
expr = Output(expr=sym.translate,
handler=handler,
verbose=True)
res = expr('German')Since we called verbose, we can also see the console print of the Output expression:
Input: (['Translate the following text into German:\n\nHello World!'],)
Expression: <bound method Symbol.translate of <class 'symai.symbol.Symbol'>(value=Hello World!)>
args: ('German',) kwargs: {'input_handler': <function OutputEngine.forward.<locals>.input_handler at ...
Dictionary: {'wrp_self': <class 'symai.components.Output'>(value=None), 'func': <function Symbol.output.<locals>._func at ...
Output: Hallo Welt!Due to limited compute resources we currently rely on OpenAI's GPT-3 API for the neuro-symbolic engine. However, given the right compute resources, it is possible to use local machines to avoid high latencies and costs, with alternative engines such as OPT or Bloom. This would allow for recursive executions, loops, and more complex expressions.
Furthermore, as we interpret all objects as symbols only with a different encodings, we integrated a set of useful engines that transform these objects to the natural language domain to perform our operations.
Although in our work, we mainly focus on how LLMs can evaluate symbolic expressions, many formal statements were already well implemented in existing symbolic engines, like WolframAlpha. Therefore, given an API KEY from WolframAlpha, we can use their engine by setting the expression_engine attribute. This avoids error prune evaluations from neuro-symbolic engines for mathematical operations. The following example shows how to use WolframAlpha to compute the result of the variable x:
expr = Expression()
expr.command(engines=['symbolic'], expression_engine='wolframalpha')
res = expr.expression('x^2 + 2x + 1'):Output:
x = -1To interpret audio files we can perform speech transcription by using whisper. The following example shows how to transcribe an audio file and return the text:
expr = Expression()
res = expr.speech('examples/audio.mp3'):Output:
I may have overslept.To "read" text from images we can perform optical character recognition (OCR) with APILayer. The following example shows how to transcribe an image and return the text:
expr = Expression()
res = expr.ocr('https://media-cdn.tripadvisor.com/media/photo-p/0f/da/22/3a/rechnung.jpg')The OCR engine returns a dictionary with a key all_text where the full text is stored. See more details in their documentation here.
:Output:
China Restaurant\nMaixim,s\nSegeberger Chaussee 273\n22851 Norderstedt\nTelefon 040/529 16 2 ...To obtain fact-based content we perform search queries via SerpApi with a Google backend. The following example shows how to search for a query and return the results:
expr = Expression()
res = expr.search('Birthday of Barack Obama'):Output:
August 4, 1961To access any data source from the web, we can use Selenium. The following example shows how to crawl a website and return the results:
expr = Expression()
res = expr.fetch(url="https://www.google.com/",
pattern="google")The pattern property can be used to detect if the document as been loaded correctly. If the pattern is not found, the crawler will timeout and return an empty result.
:Output:
GoogleKlicke hier, wenn du nach einigen Sekunden nicht automatisch weitergeleitet wirst.GmailBilderAnmelden ...To render nice images from text description we use DALL·E 2. The following example shows how to draw a text description and return the image:
expr = Expression('a cat with a hat')
res = expr.draw():Output:
https://oaidalleapiprodscus.blob.core.windows.net/private/org-l6FsXDfth6Uct ...Don't worry, we would never hide an image of a cat with a hat from you. Here is the image preview and link:
To perform file operations we use the file system of the OS. At the moment, we support only PDF files and plain text files. This is a very early stage and we are working on more sophisticated file system access and also remote storage. The following example shows how to read a PDF file and return the text:
expr = Expression()
res = expr.open('./LICENSE'):Output:
BSD 3-Clause License\n\nCopyright (c) 2023 ...We use Pinecone to index and search for text. The following example shows how to store text as an index and then retrieve the most related match of it:
expr = Expression()
expr.add(Expression('Hello World!').zip())
expr.add(Expression('I like cookies!').zip())
res = expr.get(Expression('hello').embed().value).ast()
res['matches'][0]['id']:Output:
Hello WorldHere the zip method creates a pair of strings and embedding vectors. Afterwards they are added to the index. The line with get basically retrieves the original source based on the vector value of hello and uses ast to cast the value to a dictionary.
One can set several kwargs for the indexing engine. See the symai/backend/engine_index.py file for more details.
To perform text-based image few-shot classification we use CLIP. This implementation is very experimental and conceptually does not fully integrate the way we intend it, since the embeddings of CLIP and GPT-3 are not aligned (embeddings of the same word are not identical for both models). Aligning them is an open problem for future research. For example, one could learn linear projections from one embedding space to the other.
The following example shows how to classify the image of our generated cat from above and return the results as an array of probabilities:
expr = Expression()
res = expr.vision('https://oaidalleapiprodscus.blob.core.windows.net/private/org-l6FsXDfth6...',
['cat', 'dog', 'bird', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe']):Output:
array([[9.72840726e-01, 6.34790864e-03, 2.59368378e-03, 3.41371237e-03,
3.71197984e-03, 8.53193272e-03, 1.03346225e-04, 2.08464009e-03,
1.77942711e-04, 1.94185617e-04]], dtype=float32)One can use the a locally hosted instance for the Neuro-Symbolic Engine. Out of the box we provide a Hugging Face client-server backend and host the model EleutherAI/gpt-j-6B to perform the inference. As the name suggests this is a six billion parameter model and requires a GPU with ~16GB RAM to run properly. The following example shows how to host and configure the usage of the local Neuro-Symbolic Engine.
Fist we start the backend server:
# optional: set cache folder for transformers (Linux/MacOS)
export TRANSFORMERS_CACHE="<path-to-cache-folder>"
# start server backend (default model is EleutherAI/gpt-j-6B)
symsvr
# initialize server with client call
symclientThen use once the following code to set up the local engine:
from symai.backend.engine_nesy_client import NeSyClientEngine
# setup local engine
engine = NeSyClientEngine()
setting = Expression()
setting.setup(engines={'neurosymbolic': engine})Now you can use the local engine to perform symbolic computation:
# do some symbolic computation with the local engine
sym = Symbol('cats are cute')
res = sym.compose()
...If you want to replace or extend the functionality of our framework, you can do this by customizing the existing engines or creating new engines. The Symbol class provides for this functionality some helper methods, such as command and setup. The command method can pass on configurations (as **kwargs) to the engines and change functionalities or parameters. The setup method can be used to re-initialize an engine with your custom engine implementation which must sub-class the Engine class. Both methods can be specified to address one, more or all engines.
Here is an example how to initialize your own engine. We will sub-class the existing GPT3Engine and override the prepare method. This method is called before the neural computation and can be used to modify the parameters of the actual input prompt that will be passed in for execution. In this example, we will replace the prompt with dummy text for illustration purposes:
from symai.backend.engine_gpt3 import GPT3Engine
class DummyEngine(GPT3Engine):
def prepare(self, args, kwargs, wrp_params):
wrp_params['prompts'] = ['Go wild and generate something!']
custom_engine = DummyEngine()
sym = Symbol()
sym.setup(engines={'neurosymbolic': custom_engine})
res = sym.compose()To configure an engine, we can use the command method. In this example, we will enable verbose mode, where the engine will print out what methods it is executing and the parameters it is using. This is useful for debugging purposes:
sym = Symbol('Hello World!')
sym.command(engines=['neurosymbolic'], verbose=True)
res = sym.translate('German'):Output:
<symai.backend.engine_gpt3.GPT3Engine object at 0, <function Symbol.translate.<locals>._func at 0x7fd68ba04820>, {'wrp_self': <class 'symai.symbol.S ['\n\nHallo Welt!']Here is the list of names of the engines that are currently supported:
neurosymbolic- GPT-3symbolic- WolframAlphaocr- Optical Character Recognitionvision- CLIPspeech- Whisperembedding- OpenAI Embeddings API (ada-002)userinput- User Command Line Inputsearch- SerpApi (Google search)crawler- Seleniumexecute- Python Interpreterindex- Pineconeopen- File Systemoutput- Output Callbacks (e.g. for printing to console or storage)imagerendering- DALL·E 2
Finally, let's assume you want to create a entirely new engine, but still keep our workflow, then you can use the _process_query function from symai/functional.py and pass in your engine including all other specified objects (i.e. Prompt, PreProcessor, etc.; see also section Custom Operations).
Uff... this is a long list. We are still in the early stages of development and are working hard to overcome these limitations. Just to name a few:
Engineering challenges:
- Our framework is still in its early stages of development and is not yet meant for production use. For example, the Stream class only estimates the prompt size by an approximation, which sometimes can fail. One can also create more sophisticated prompt hierarchies and dynamically adjust the global context based on a state-based approach. This would allow making consistent predictions even for long text streams.
- Many operations need to be further improved: verified for biases, fairness, robustness, etc.
- The code may not be complete and is not yet optimized for speed and memory usage, and uses API-based LLMs due to limitations of compute resources.
- Code coverage is not yet complete and we are still working on the documentation.
- Integrate with a more diverse set of models from Hugging Face or other platforms.
- Currently we did not account for multi-threading and multi-processing.
Research challenges:
- To reliably use our framework, one needs to further explore how to fine-tune LLMs to specifically solve many of the proposed operations in a more robust and efficient way.
- The experimental integration of CLIP is meant to align image and text embeddings. To enable decision-making of LLMs based on observations and perform symbolic operations on objects in images or videos would be a huge leap forward. This would perfectly integrate with reinforcement learning approaches and enable us to control policies in a systematic way (see also GATO). Therefore, we need to train large multi-modal variants with image / video data and text data, describing in high details the scenes to obtain neuro-symbolic computation engines that can perform semantic operations similar to
move-towards-tree,open-door, etc. - Generalist LLMs are still highly over-parameterized and hardware has not yet caught up to host these models on arbitrary day-to-day machines. This limits the applicability of our approach not only on small data streams, but also gives high latencies and therefore limits the amount of complexity and expressiveness we can achieve with our expressions.
We are constantly working on improving the framework and are open to any suggestions, feedback or comments. However, we try to think ahead of time and have some general ideas for future work in mind:
- Meta-Learning Semantic Concepts on top of Neuro-Symbolic Expressions
- Self-evolving and self-healing API
- Integrate our neuro-symbolic framework with Reinforcement Learning
We believe that LLMs as neuro-symbolic computation engines enable us a new class of applications, with tools and APIs that can self-analyze and self-heal. We are excited to see what the future brings and are looking forward to your feedback and contributions.
We have presented a neuro-symbolic view on LLMs and showed how they can be a central pillar for many multi-modal operations. We gave an technical report on how to utilize our framework and also hinted at the capabilities and prospects of these models to be leveraged by modern software development.
This project is inspired by the following works, but not limited to them:
- Newell and Simon's Logic Theorist: Historical Background and Impact on Cognitive Modeling
- Search and Reasoning in Problem Solving
- The Algebraic Theory of Context-Free Languages
- Tracr: Compiled Transformers as a Laboratory for Interpretability
- How can computers get common sense?
- Artificial Intelligence: A Modern Approach
- SymPy: symbolic computing in Python
- Neuro-symbolic programming
- Fuzzy Sets
- An early approach toward graded identity and graded membership in set theory
- From Statistical to Causal Learning
- Language Models are Few-Shot Learners
- Deep reinforcement learning from human preferences
- Aligning Language Models to Follow Instructions
- Chain of Thought Prompting Elicits Reasoning in Large Language Models
- Measuring and Narrowing the Compositionality Gap in Language Models
- Large Language Models are Zero-Shot Reasoners
- Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
- ReAct: Synergizing Reasoning and Acting in Language Models
- Understanding Stereotypes in Language Models: Towards Robust Measurement and Zero-Shot Debiasing
- Connectionism and Cognitive Architecture: A Critical Analysis
- Unit Testing for Concepts in Neural Networks
- Teaching Algorithmic Reasoning via In-context Learning
- REALM: Retrieval-Augmented Language Model Pre-Training
- Wolfram|Alpha as the Way to Bring Computational Knowledge Superpowers to ChatGPT
- Build a GitHub support bot with GPT3, LangChain, and Python
Since an often received request is to state the differences between our project and LangChain, this is a short list and by no means complete to contrast ourselves to other frameworks:
- We focus on cognitive science and cognitive architectures research, and therefore, do not consider our framework as a production-ready implementation. We believe that the current state of the art in LLMs is not yet ready for general purpose tasks, and therefore, we focus on the advances of concept learning, reasoning and flow control of the generative process.
- We consider LLMs as one type of neuro-symbolic computation engines, which could be of any shape or form, such as knowledge graphs, rule-based systems, etc., therefore, not necessarily limited to Transformers or LLMs.
- We focus on advancing the development of programming languages and new programming paradigms, and subsequently its programming stack, including neuro-symbolic design patterns to integrate with operators, inheritance, polymorphism, compositionality, etc. Classical object-oriented and compositional design pattern have been well studied in the literature, however, we bring a novel view on how LLMs integrate and augment fuzzy logic and neuro-symbolic computation.
- We do not consider our main attention towards prompt engineering. Our proposed prompt design helps the purpose to combine object-oriented paradigms with machine learning models. We believe that prompt misalignments in their current form will alleviate with further advances in Reinforcement Learning from Human Feedback and other value alignment methods. Therefore, these approaches will solve the necessity to prompt engineer or the ability to prompt hack statements. Consequently, this will result to much shorter zero- or few-shot examples (at least for small enough tasks). This is where we see the power of a divide a conquer approach, performing basic operations and re-combining them to solve the complex tasks.
- We see operators / methods as being able to move along a spectrum between prompting and fine-tuning, based on task-specific requirements and availability of data. We believe that this is a more general approach, compared to prompting frameworks.
- We propose a general approach how to handle large context sizes and how to transform a data stream problem into a search problem, related to the reasoning as a search problem in Search and Reasoning in Problem Solving.
We also want to state, that we highly value and support the further development of LangChain. We believe that for the community they offer very important contributions and help advance the commercialization of LLMs. We hope that our work can be seen as complementary, and future outlook on how we would like to use machine learning models as an integral part of programming languages and therefore its entire computational stack.
Also this is a long list. Great thanks to my colleagues and friends at the Institute for Machine Learning at Johannes Kepler University (JKU), Linz for their great support and feedback; great thanks to Dynatrace Research for supporting this project. Thanks also to the AI Austria RL Community. Thanks to all the people who contributed to this project. Be it by providing feedback, bug reports, code, or just by using the framework. We are very grateful for your support.
And finally, thanks to the open source community for making their APIs and tools available to the public, including (but not exclusive to) PyTorch, Hugging Face, OpenAI, GitHub, Microsoft Research, and many more.
Special thanks to the contributions from Kajetan Schweighofer, Markus Hofmarcher, Thomas Natschläger and Sepp Hochreiter.
If you want to contribute to this project, please read the CONTRIBUTING.md file for details on our code of conduct, and the process for submitting pull requests to us. Any contributions are highly appreciated.
@software{Dinu_SymbolicAI_2022,
author = {Dinu, Marius-Constantin},
title = {{SymbolicAI: A Neuro-Symbolic Perspective on Large Language Models (LLMs)}},
url = {https://github.com/Xpitfire/symbolicai},
month = {11},
year = {2022}
}This project is licensed under the BSD-3-Clause License - see the LICENSE file for details.
If you like this project, leave a star ⭐️ and share it with your friends and colleagues. And if you want to support this project even further, please consider donating to support the continuous development of this project. Thank you!
We are also looking for contributors or investors to grow and support this project. If you are interested, please contact us.
If you have any questions about this project, please contact us via email, on our website or find us on Discord:
If you want to contact me directly, you can reach me directly on LinkedIn, on Twitter, or at my personal website.