
Overview • Installation • Paper • Examples • Docs • Citation
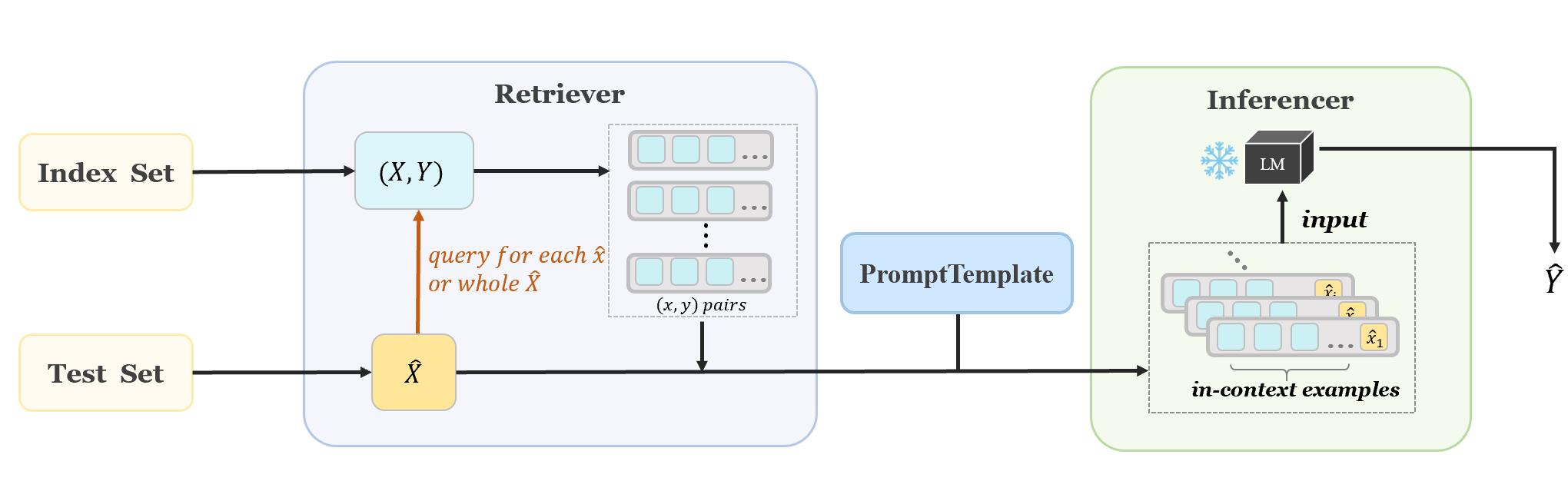
OpenICL provides an easy interface for in-context learning, with many state-of-the-art retrieval and inference methods built in to facilitate systematic comparison of LMs and fast research prototyping. Users can easily incorporate different retrieval and inference methods, as well as different prompt instructions into their workflow.
- v0.1.8 Support LLaMA and self-consistency
Note: OpenICL requires Python 3.8+
Using Pip
pip install openicl
Installation for local development:
git clone https://github.com/Shark-NLP/OpenICL
cd OpenICL
pip install -e .
Following example shows you how to perform ICL on sentiment classification dataset. More examples and tutorials can be found at examples
from datasets import load_dataset
from openicl import DatasetReader
# Loading dataset from huggingface
dataset = load_dataset('gpt3mix/sst2')
# Define a DatasetReader, with specified column names where input and output are stored.
data = DatasetReader(dataset, input_columns=['text'], output_column='label')from openicl import PromptTemplate
tp_dict = {
0: "</E>Positive Movie Review: </text>",
1: "</E>Negative Movie Review: </text>"
}
template = PromptTemplate(tp_dict, {'text': '</text>'}, ice_token='</E>')The placeholder </E> and </text> will be replaced by in-context examples and testing input, respectively. For more detailed information about PromptTemplate (such as string-type template) , please see tutorial1.
from openicl import TopkRetriever
# Define a retriever using the previous `DataLoader`.
# `ice_num` stands for the number of data in in-context examples.
retriever = TopkRetriever(data, ice_num=8)Here we use the popular TopK method to build the retriever.
from openicl import PPLInferencer
inferencer = PPLInferencer(model_name='distilgpt2')from openicl import AccEvaluator
# the inferencer requires retriever to collect in-context examples, as well as a template to wrap up these examples.
predictions = inferencer.inference(retriever, ice_template=template)
# compute accuracy for the prediction
score = AccEvaluator().score(predictions=predictions, references=data.references)
print(score)(updating...)
If you find this repository helpful, feel free to cite our paper:
@article{wu2023openicl,
title={OpenICL: An Open-Source Framework for In-context Learning},
author={Zhenyu Wu, Yaoxiang Wang, Jiacheng Ye, Jiangtao Feng, Jingjing Xu, Yu Qiao, Zhiyong Wu},
journal={arXiv preprint arXiv:2303.02913},
year={2023}
}