-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
69 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,69 @@ | ||
| --- | ||
| title: Attention 机制与后续应用 | ||
| date: 2021-09-28 16:37:51 | ||
| permalink: /attention-and-transformer/ | ||
| cover: https://xerrors.oss-cn-shanghai.aliyuncs.com/imgs/20220306093337.png | ||
| tags: | ||
| - Attention | ||
| - Transformer | ||
| - NLP | ||
| categories: 人工智能 | ||
| --- | ||
| 报告PPT:[Attention 机制与Transformer、DETR.pptx](https://xerrors.oss-cn-shanghai.aliyuncs.com/files/reports/Attention%E4%B8%8ETransformer.pptx) | ||
|
|
||
| ## 1. Attention 机制 | ||
|
|
||
| - 由来(原理上、视觉解释)[https://zhuanlan.zhihu.com/p/35571412](https://zhuanlan.zhihu.com/p/35571412)、[https://easyai.tech/ai-definition/attention/](https://easyai.tech/ai-definition/attention/) | ||
|
|
||
| - 来源于生物学上的视觉特征 attention机制的本质是从人类视觉注意力机制中获得灵感(可以说很‘以人为本’了)。大致是我们视觉在感知东西的时候,一般不会是一个场景从到头看到尾每次全部都看,而往往是根据需求观察注意特定的一部分。而且当我们发现一个场景经常在某部分出现自己想观察的东西时,我们就会进行学习在将来再出现类似场景时把注意力放到该部分上。这可以说就是注意力机制的本质内容了。核心逻辑就是「**从关注全部到关注重点**」(配图热力图) | ||
| - 调控关注重心的方法就是**加权;** | ||
| - 解决的问题、痛点 [https://zhuanlan.zhihu.com/p/47063917](https://zhuanlan.zhihu.com/p/47063917) | ||
|
|
||
| - 计算能力的限制,当要记住很多“信息“,模型就要变得更复杂,然而目前计算能力依然是限制神经网络发展的瓶颈。 | ||
| - RNN机制实际中存在长程梯度消失的问题,encoder过程将输入的句子转换为语义中间件,decoder过程根据语义中间件和之前的单词输出,依次输出最有可能的单词组成句子。对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,比如长度为10的文本和长度为1000的文本,所蕴含的信息量必然是不一样的。图源自:[https://www.jianshu.com/p/1d67638139da](https://www.jianshu.com/p/1d67638139da) | ||
|
|
||
|  | ||
|
|
||
|  | ||
| - 使用的场景 | ||
|
|
||
| - 为了解决这一由长序列到定长向量转化而造成的信息损失的瓶颈,Attention注意力机制被引入了。Attention机制跟人类翻译文章时候的思路有些类似,即将注意力关注于我们翻译部分对应的上下文。同样的,Attention模型中,当我们翻译当前词语时,我们会寻找源语句中相对应的几个词语,并结合之前的已经翻译的部分作出相应的翻译,如下图所示,当我们翻译“knowledge”时,只需将注意力放在源句中“知识”的部分,当翻译“power”时,只需将注意力集中在"力量“。这样,当我们decoder预测目标翻译的时候就可以看到encoder的所有信息,而不仅局限于原来模型中定长的隐藏向量,并且不会丧失长程的信息。图源:[https://zhuanlan.zhihu.com/p/47063917](https://zhuanlan.zhihu.com/p/47063917) | ||
|
|
||
|  | ||
| - self-attention 与 Transformer | ||
|
|
||
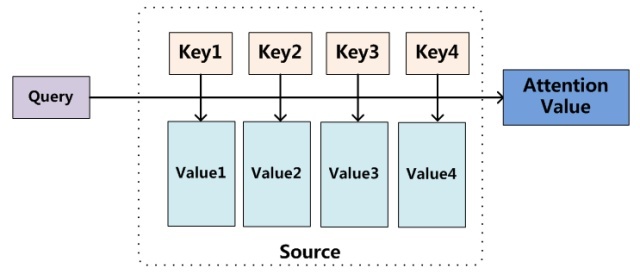
| - Attention机制其实就是一系列注意力分配系数,也就是一系列权重参数,权重的计算往往是使用 $Attention Value = \operatorname{similarity}(Q K^T)V$ 图源:[https://zhuanlan.zhihu.com/p/35571412](https://zhuanlan.zhihu.com/p/35571412) | ||
|
|
||
|  | ||
|
|
||
|  | ||
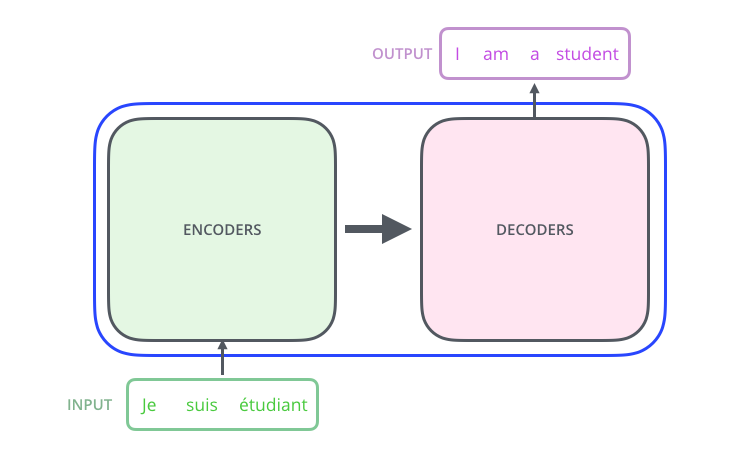
| - Transformer | ||
|
|
||
| - self-attention 计算 强烈推荐图示:[https://jalammar.github.io/illustrated-transformer/](https://jalammar.github.io/illustrated-transformer/) | ||
|
|
||
| 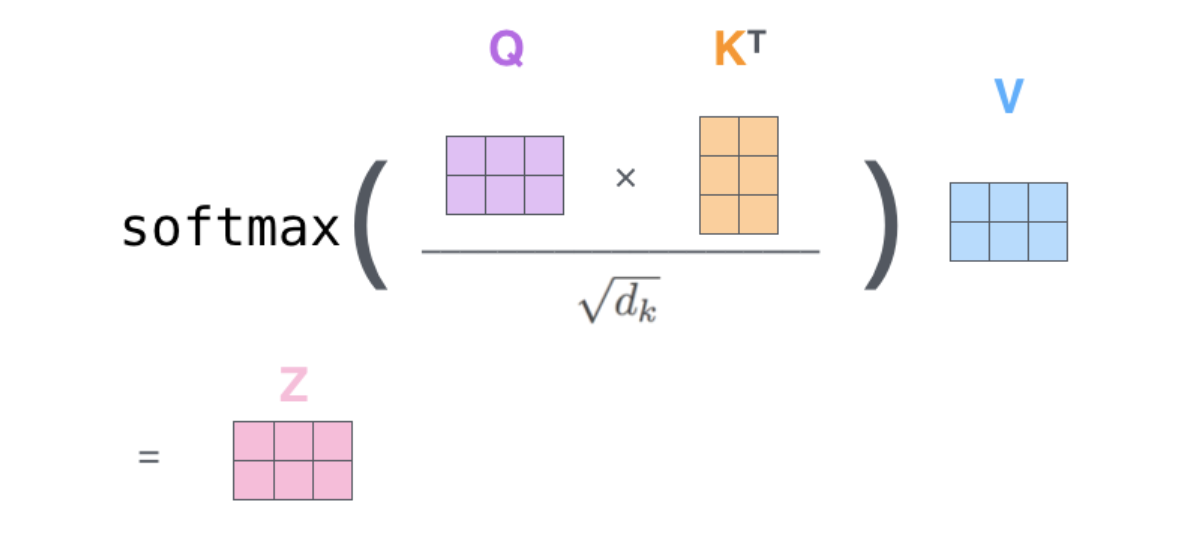 | ||
|
|
||
| 源自:《A Survey of Transformers》复旦大学 邱锡鹏教授 | ||
|
|
||
| 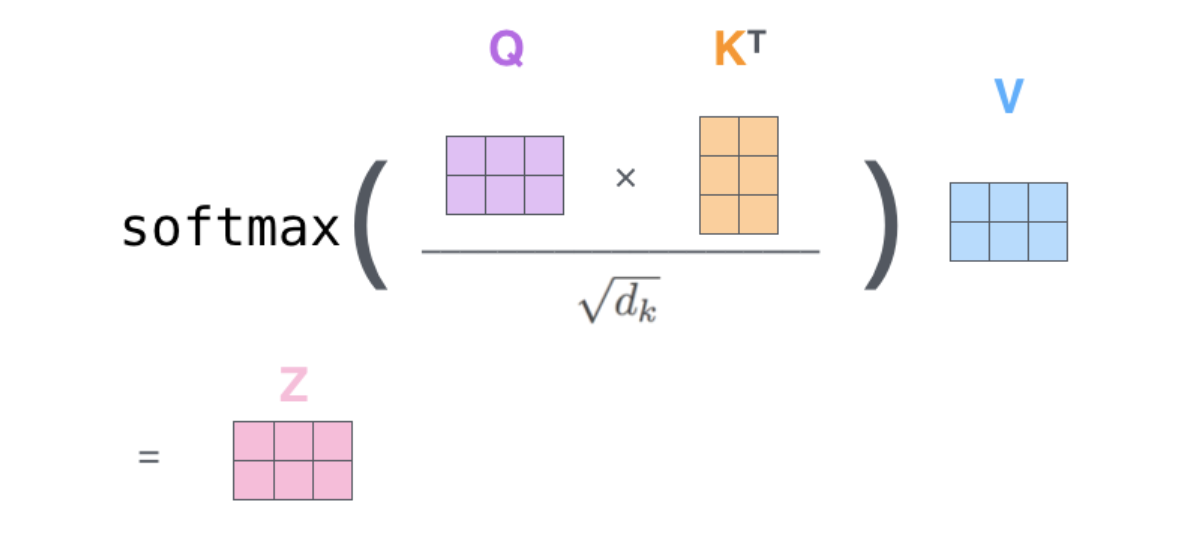 | ||
|
|
||
|  | ||
|
|
||
|  | ||
|
|
||
| 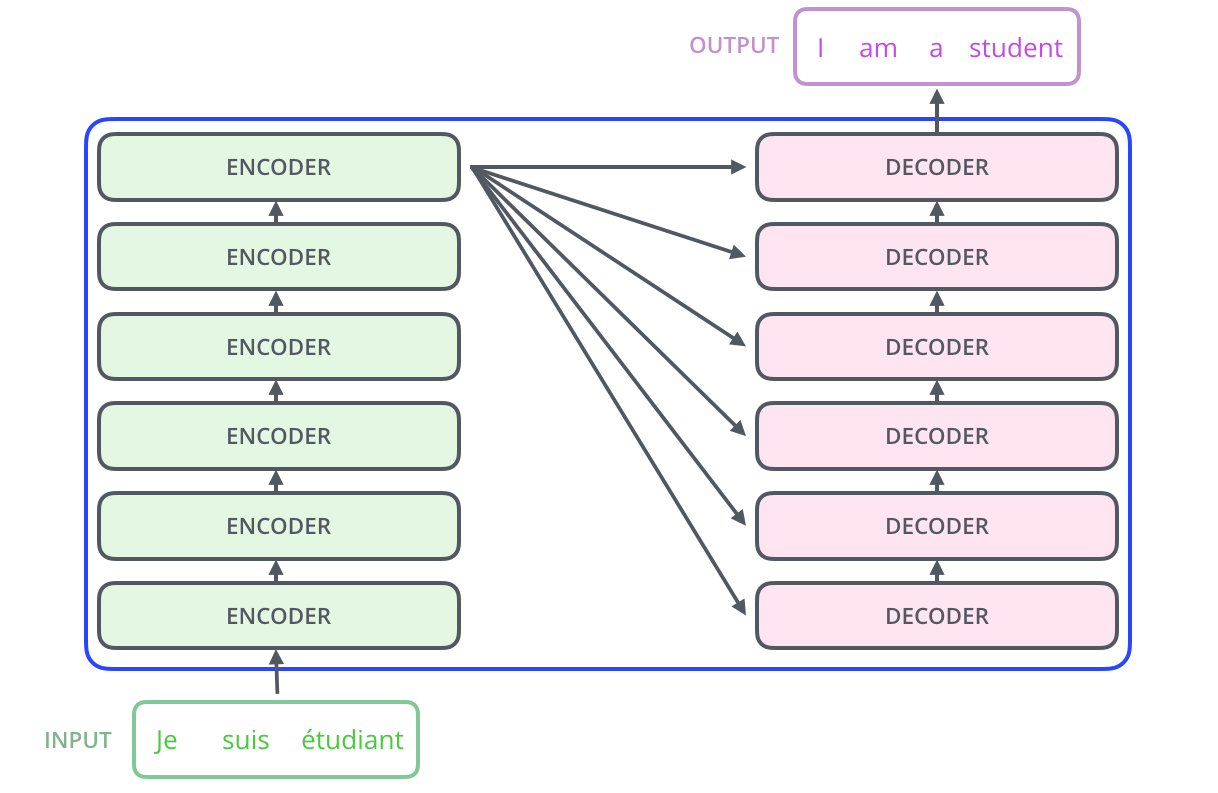 | ||
|
|
||
| - 优点、缺点: | ||
| - 一步到位的全局联系捕捉,上文说了一些,attention机制可以灵活的捕捉全局和局部的联系,而且是一步到位的。另一方面从attention函数就可以看出来,它先是进行序列的每一个元素与其他元素的对比,在这个过程中每一个元素间的距离都是一,因此它比时间序列RNNs的一步步递推得到长期依赖关系好的多,越长的序列RNNs捕捉长期依赖关系就越弱。 | ||
| - 相较于 RNN 和 CNN,模型复杂度小,参数少;且参数量是不依赖于输入长度的。(计算量依赖于输入长度)参考这里:[https://www.zhihu.com/question/445895638](https://www.zhihu.com/question/445895638) | ||
| - 并行计算减少模型训练时间;Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。但是CNN也只是每次捕捉局部信息,通过层叠来获取全局的联系增强视野。 | ||
|
|
||
| ## 参考资料 | ||
|
|
||
| [1] [浅谈Attention机制的理解](https://zhuanlan.zhihu.com/p/35571412) | ||
|
|
||
| [2] [attention机制原理及简单实现](https://www.jianshu.com/p/1d67638139da) | ||
|
|
||
| [3] [一文看懂 Attention(本质原理+3大优点+5大类型) - 产品经理的人工智能学习库](https://easyai.tech/ai-definition/attention/) | ||
|
|
||
| [4] [Attention机制详解(一)--Seq2Seq中的Attention](https://zhuanlan.zhihu.com/p/47063917) |