
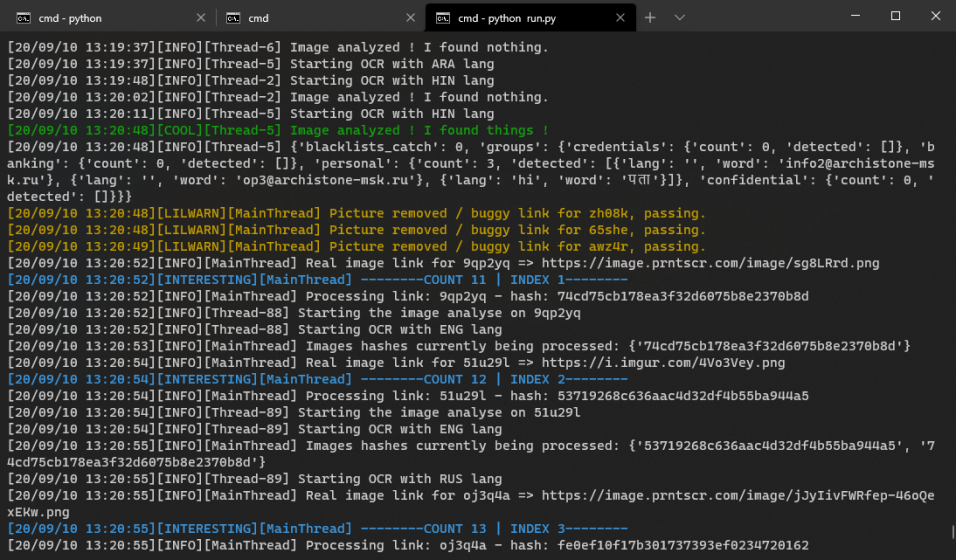
Darkshot is a scraper tool on steroids, to analyze all of the +2 Billions pictures publicly available on Lightshot.
It uses OCR to analyze pictures and auto-categorize them thanks to keywords and detection functions.
You can find pretty much everything : credentials, personal informations (emails, phone numbers, addresses, ID cards, passeports), banking information, etc.
Since it's modulable, you can make your own detection function and use it as a monitoring tool.
👉 Multi-threading
👉 Anti-conflicting threads protection
👉 Auto-saving and resuming session
👉 3 links generators : Ascending, Descending and Random
👉 Auto-translating keywords
👉 Auto-analyzing pictures with multiple OCR langs
👉 Auto-downloading OCR langs training data
👉 Auto-categorizing pictures with keywords, groups and detection functions
👉 Auto-exporting pictures per groups with their statistics in HTML
👉 Modulable : add your own detection functions and keywords

C:\Users\mxrch\Desktop\darkshot-beta>python run.py -h
Usage: run.py [OPTIONS]
Options:
-t, --threads INTEGER Number of threads [default: 5]
-m, --mode TEXT The mode to catch the more recent link, using it as a
limit. (noisy, stealth)
- noisy : it uploads a picture to get the more recent
link
- stealth : it uses the last link shown on Twitter
here : https://prntscr.com/twitter.json [default:
noisy]
-a, --algo TEXT Algorithm used to generate links. (ascending,
descending, random) [default: descending]
-d, --debug Verbose mode, for debugging. [default: False]
-ro, --resume_ro Don't save the resume state, only read it. [default:
False]
-c, --clean TEXT Clean some things you don't want anymore. (logs,
resume, exports)
If you want want to specify multiple values, specify
them comma-separated and without spaces. Ex: "--clean
logs,exports"
-h, --help Show this message and exit.
$ python run.py -t 5 -m stealth -a descending- Python 3.4+ would be ok. (I developed it with Python 3.8.1)
- Tesseract
- These Python modules :
httpx
googletrans
pytesseract
opencv-python
pillow
scrapy
termcolor
beautifultable
reprint
click
json
shutil
imghdr
hashlib
You'll find installation instructions for all main plateforms here : https://github.com/tesseract-ocr/tesseract/wiki
Don't forget to add tesseract to your PATH.
$ git clone https://github.com/mxrch/darkshot
$ cd darkshot
$ python -m pip install -r requirements.txtThen, we need to check if the choosen OCR langs in config.py are installed, and if not, it will auto-download and install them.
- Run the file check_ocr_langs.py as Administrator.
If it tells you that it's okay, then it's okay. 🧠
You are ready !
There is a config.py file where you can configure almost everything, like the keywords to be translated, the OCR langs data to use, the resume state margin protection, the timeouts, the threads results delimiter (to avoid overloading the RAM), etc.
Basically, the program keep every current processing link in a variable, and pass it in a function that save it if it detects an exception, like a CTRL+C.
But there is a problem.
Imagine you have 5 threads running, it will keep the last link given to the last thread, even if the thread has not finished.
So, you'll restart the program from after this link, and you will never really get the results from this link.
This is where this protection plays its role, it will consistently keep an arbitrary margin between the last link and some links back.
To calculate it, it sums the number of threads with the value in config.py.
While we don't end the threads, their results are kept in the memory.
Since Darkshot is designed to keep running several years, we can't keep the threads results indefinitly in the memory.
So, it takes the value in config.py (example: 100), and it will unload and restart threads each 100 links.
More simple, it justs calculate the hashes of all pictures in this folder (and subfolders), and if a Lightshot picture has one of these hashes, it don't process it.
It's like a blacklist but for pictures.
All the detection stuff is in the lib/detection.py file.
By default, I made 3 detection functions:
- The basic detection (just check if the string is in the text)
- The isolated detection (it checks if the string is in the text and if he is between 2 non-alphanumeric characters)
- The regex detection (it checks if the regex finds something valid)
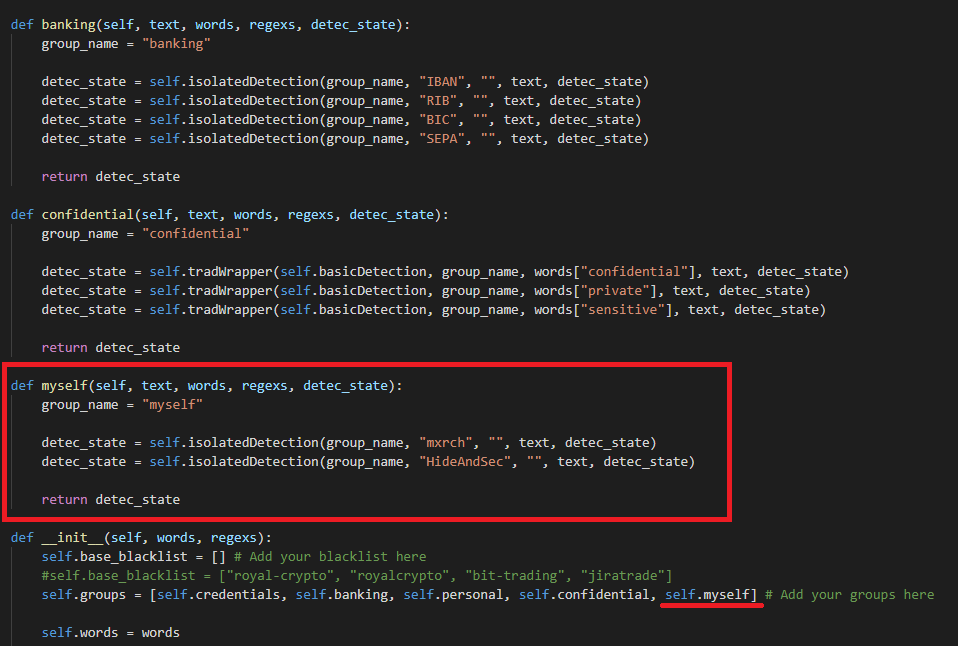
- Go in the file and look at the class, you'll see some functions and then the Groups detection functions (credentials, personal, banking and confidential).
- For your first detection group, you can simply copy & paste below the confidential group function.
- Change the function name to your desired name, as well as the "group_name" variable below.
- Then, you just put the detection functions you want with your keywords in it, where you see the
detec_statevariables. - You now can add your group in
self.groups, inside the__init__function. If your function is named secretsaliens, putself.secretsaliens.
Voilà, your group is added and functional !

There are two kinds of blacklists :
- The base blacklist, which runs on every detection, whatever the group
- The group blacklist, which runs only within the group it was assigned at.
Imagine if you want to detect pictures of conversation where they are talking about aliens but not related to the Area 51.
- First, you can create a detection group relating to the area 51 by simply detecting the string "area 51",
- Then you can simply add your blacklisted word like this in the
blacklist_groupsarray within thegenBlacklistsfunction:

And then, for every picture detected in the area51 detection group, if the string "alien" is present in it, it will not save it.
- Simply add your string here :

And it will not save the picture if this string is detected.
You can find them here :

If you want to make your own detection function, you can :
- Copy & paste the "basicDetection" function below.
- Next, you can modify the conditions and everything you want.
You only need to keep the function args, and the return of detec_state if the detection finds nothing.
Otherwise, you can return the updated state like this : return self.updateState(group=group, word=word, lang=lang, detec_state=detec_state)
If you want to use every translation of a certain word with your detection function, you can transform your function call from this :
detec_state = self.basicDetection(group_name, "password", "", text, detec_state)
To this :
detec_state = self.tradWrapper(self.basicDetection, group_name, words["password"], text, detec_state)
Be sure that you added your word in the words_to_translate of the config.py file.
This tool is intended for an education usage only, I am not responsible of a possible bad usage of it.
Its main goal is to demonstrate the danger of storing user data with incremental/guessable links, and I wanted to push the thing to the max.
This Lightshot issue is known since many years.
PS : I started this project 2 months ago and I didn't saw this project at all before writing this Readme : https://github.com/utkusen/shotlooter
But you can check that we don't have the same code at all. I hope the two projects complement each other. 🙏
- @hexabeast for his cool multi-threading class
- @caracali, @elweth-sec and @dutyfruit for beta-testing on linux & mac.
- the HideAndSec team for motivation. ❤️