forked from HIT-SCIR/ltp
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
add other language session in document
- Loading branch information
Showing
1 changed file
with
12 additions
and
96 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,9 +1,11 @@ | ||
| LTP使用文档v3.0 | ||
| =============== | ||
|
|
||
| #### 作者 | ||
| #### 更新信息 | ||
|
|
||
| * 刘一佳 << [email protected] >> 2014年6月14日,增加使用其他语言调用ltp一节 | ||
| * 牛国成 << [email protected] >> 2014年5月10日,增加词性词典相关文档 | ||
| * 韩冰 << [email protected] >> 2014年1月16日,增加模型裁剪相关文档 | ||
| * 刘一佳 << [email protected] >> 2013年7月17日,创建文档 | ||
|
|
||
| 版权所有:哈尔滨工业大学社会计算与信息检索研究中心 | ||
|
|
@@ -13,6 +15,7 @@ LTP使用文档v3.0 | |
| * [开始使用LTP](#开始使用LTP) | ||
| * [使用ltp_test以及模型](#使用ltp_test以及模型) | ||
| * [编程接口](#编程接口) | ||
| * [使用其他语言调用ltp](#使用其他语言调用ltp) | ||
| * [使用ltp_server](#使用ltp_server) | ||
| * [实现原理与性能](#实现原理与性能) | ||
| * [使用训练套件](#使用训练套件) | ||
|
|
@@ -26,101 +29,6 @@ LTP使用文档v3.0 | |
|
|
||
| 2011年6月1日,为了与业界同行共同研究和开发中文信息处理核心技术,我中心正式将LTP开源。 | ||
|
|
||
| # 开始使用LTP | ||
| 如果你是第一次使用LTP,不妨花一些时间了解LTP能帮你做什么。 | ||
|
|
||
| LTP提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作。从应用角度来看,LTP为用户提供了下列组件: | ||
|
|
||
| * 针对单一自然语言处理任务,生成统计机器学习模型的工具 | ||
| * 针对单一自然语言处理任务,调用模型进行分析的编程接口 | ||
| * 使用流水线方式将各个分析工具结合起来,形成一套统一的中文自然语言处理系统 | ||
| * 系统可调用的,用于中文语言处理的模型文件 | ||
| * 针对单一自然语言处理任务,基于云端的编程接口 | ||
|
|
||
| 如果你的公司需要一套高性能的中文语言分析工具以处理海量的文本,或者你的在研究工作建立在一系列底层中文自然语言处理任务之上,或者你想将自己的科研成果与前沿先进工作进行对比,LTP都可能是你的选择。 | ||
|
|
||
| ## 如何安装LTP | ||
|
|
||
| 下面的文档将介绍如何安装LTP | ||
|
|
||
| ### 获得LTP | ||
|
|
||
| 作为安装的第一步,你需要获得LTP。LTP包括两部分,分别是项目源码和编译好的模型文件。你可以从以下链接获得最新的LTP项目源码。 | ||
|
|
||
| * Github项目托管:[https://github.com/HIT-SCIR/ltp/releases](https://github.com/HIT-SCIR/ltp/releases) | ||
|
|
||
| 同时,你可以从以下一些地方获得LTP的模型。 | ||
|
|
||
| * [百度云](http://pan.baidu.com/share/link?shareid=1988562907&uk=2738088569) | ||
| * 当前模型版本3.1.0 | ||
|
|
||
| ### 安装CMake | ||
|
|
||
| LTP使用编译工具CMake构建项目。在安装LTP之前,你需要首先安装CMake。CMake的网站在[这里](http://www.cmake.org)。如果你是Windows用户,请下载CMake的二进制安装包;如果你是Linux,Mac OS或Cygwin的用户,可以通过编译源码的方式安装CMake,当然,你也可以使用Linux的软件源来安装。 | ||
|
|
||
| ### Windows(MSVC)编译 | ||
|
|
||
| 第一步:构建VC Project | ||
|
|
||
| 在项目文件夹下新建一个名为build的文件夹,使用CMake Gui,在source code中填入项目文件夹,在binaries中填入build文件夹。然后Configure -> Generate。 | ||
|
|
||
| 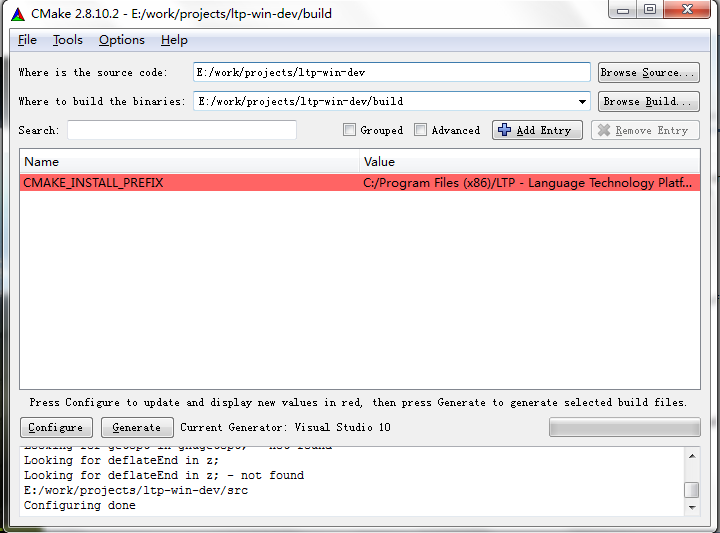 | ||
|
|
||
| 或者在命令行build 路径下运行 | ||
|
|
||
| cmake .. | ||
|
|
||
| 第二步:编译 | ||
|
|
||
| 构建后得到ALL_BUILD、RUN_TESTS、ZERO_CHECK三个VC Project。使用VS打开ALL_BUILD项目,选择Release(*)方式构建项目。 | ||
|
|
||
| (注*:boost::multi_array与VS2010不兼容的bug已经在3.1.0中得到修复,3.1.x及以上版本已经可以使用Debug方式构建,但出于效率考虑,仍旧建议使用Release方式构建。) | ||
|
|
||
| ### Linux,Mac OSX和Cygwin编译 | ||
|
|
||
| Linux、Mac OSX(*)和Cygwin的用户,可以直接在项目根目录下使用命令 | ||
|
|
||
|
|
||
| ./configure | ||
| make | ||
|
|
||
| (注:Mac OSX如果要编译example下的示例程序,请加入-std=c++11 -stdlib=libstdc++ -Wno-error=c++11-narrowing选项) | ||
|
|
||
| 进行编译。 | ||
|
|
||
| ## 简单地试用 | ||
|
|
||
| 编译成功后,会在./bin文件夹下生成如下一些二进制程序: | ||
|
|
||
| | 程序名 | 说明 | | ||
| | ------ | ---- | | ||
| | ltp_test | LTP调用程序 | | ||
| | ltp_server* | LTP Server程序 | | ||
|
|
||
| 在lib文件夹下生成以下一些静态链接库(**) | ||
|
|
||
| | 程序名 | 说明 | | ||
| | ------ | ---- | | ||
| | splitsnt.lib | 分句lib库 | | ||
| | segmentor.lib | 分词lib库 | | ||
| | postagger.lib | 词性标注lib库 | | ||
| | parser.lib | 依存句法分析lib库 | | ||
| | ner.lib | 命名实体识别lib库 | | ||
| | srl.lib | 语义角色标注lib库 | | ||
|
|
||
| 同时,在tools/train文件夹下会产生如下一些二进制程序: | ||
|
|
||
| | 程序名 | 说明 | | ||
| | ------ | ---- | | ||
| | otcws | 分词的训练和测试套件 | | ||
| | otpos | 词性标注的训练和测试套件 | | ||
| | otner | 命名实体识别的训练和测试套件 | | ||
| | lgdpj | 依存句法分析训练和测试套件 | | ||
| | lgsrl | 语义角色标注训练和测试套件 | | ||
|
|
||
| * (注*:在window版本中ltp_server、Maxent、SRLExtract、SRLGetInstance并不被编译。) | ||
| * (注**:window下产生的静态库的后缀是.lib,linux下产生的静态库的后缀是.a) | ||
|
|
||
| # 使用ltp_test以及模型 | ||
| 一般来讲,基于统计机器学习方法构建的自然语言处理工具通常包括两部分,即:算法逻辑以及模型。模型从数据中学习而得,通常保存在文件中以持久化;而算法逻辑则与程序对应。 | ||
|
|
||
|
|
@@ -572,6 +480,14 @@ lexicon_file参数指定的外部词典文件样例如下所示。每行指定 | |
|
|
||
| ## 语义角色标注接口 | ||
|
|
||
| # 使用其他语言调用ltp | ||
| 如果您希望在本地使用除C++之外的其他语言调用ltp,我们针对常用语言对ltp进行了封装。 | ||
|
|
||
| * Java: [ltp4j<sup>beta</sup>: Language Technology Platform for Java](https://github.com/HIT-SCIR/ltp4j) | ||
| * Python:[pyltp<sup>beta</sup>: the python extension for LTP](https://github.com/HIT-SCIR/pyltp) | ||
|
|
||
| 详细使用方法,请参考各项目文档。 | ||
|
|
||
| # 使用ltp_server | ||
| ## 重要注意 | ||
|
|
||
|
|
||