A memory-efficient optimizer designed for large language model (LLM) pre-training and full-parameter fine-tuning, offering SGD-like memory cost with AdamW-level performance.
🔗 Paper • Project Page

-
[2024/12] We are working on integrating APOLLO into LLaMA-Factory.
-
[2024/12] We are happy to release the official implementation of APOLLO v1.0.0 in PyPI (see here). We support QAPOLLO using int8 weight quantization from Q-Galore.
-
[2024/12] APOLLO validated by third-party Julia implementation!: Our APOLLO optimizer has been independently validated by a third party using a Julia implementation. Check out the post. They are also working to integrate APOLLO into FluxML.
-
[2024/12] APOLLO Paper Released: Our paper is now available on arXiv! Check it out here: [Paper].
We introduce APOLLO (Approximated Gradient Scaling for Memory Efficient LLM Optimization), a novel method designed to optimize the memory efficiency of training large language models (LLM), offering SGD-like memory cost while delivering AdamW-level performance for both pre-training and finetuning!
APOLLO effectively integrates two major ideas for memory-efficient LLM training: low-rank approximation (GaLore) and optimizer state redundancy reduction (Adam-mini). However, APOLLO takes memory efficiency to a new level, achieving significant memory savings (below GaLore and its variants, and close to SGD) while maintaining or surpassing the performance of Adam(W).
Our key contributions include:
-
Structured Learning Rate Updates for LLM Training: We identify that structured learning rate updates, such as channel-wise or tensor-wise scaling, are sufficient for LLM training. This approach explores redundancy in AdamW's element-wise learning rate update rule, forming a basis for our APOLLO method.
-
Approximated Channel-wise Gradient Scaling in a Low-Rank Auxiliary Space (APOLLO):
APOLLO proposes a practical and memory-efficient method to approximate channel-wise gradient scaling factors in an auxiliary low-rank space using pure random projections. This method achieves superior performance compared to AdamW, even with lower-rank approximations, while maintaining excellent memory efficiency. -
Minimal-Rank Tensor-wise Gradient Scaling (APOLLO-Mini):
APOLLO-Mini introduces extreme memory efficiency by applying tensor-wise gradient scaling using only a rank-1 auxiliary sub-space. This results in SGD-level memory costs while outperforming AdamW, showcasing the effectiveness of the approach.
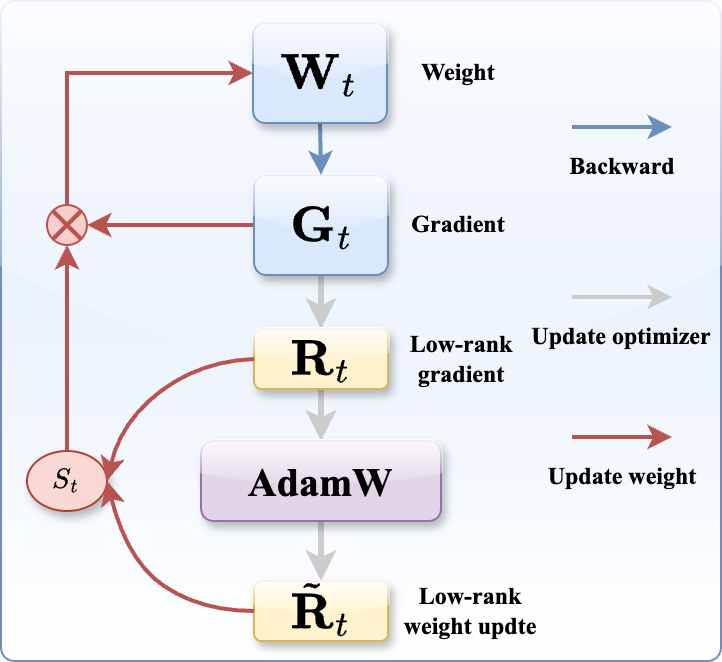
Figure 1: The APOLLO Framework for Memory-Efficient LLM Training. The channel-wise or tensor-wise gradient scaling factor is obtained via an auxiliary low-rank optimizer state, constructed using pure random projection (no SVD required).
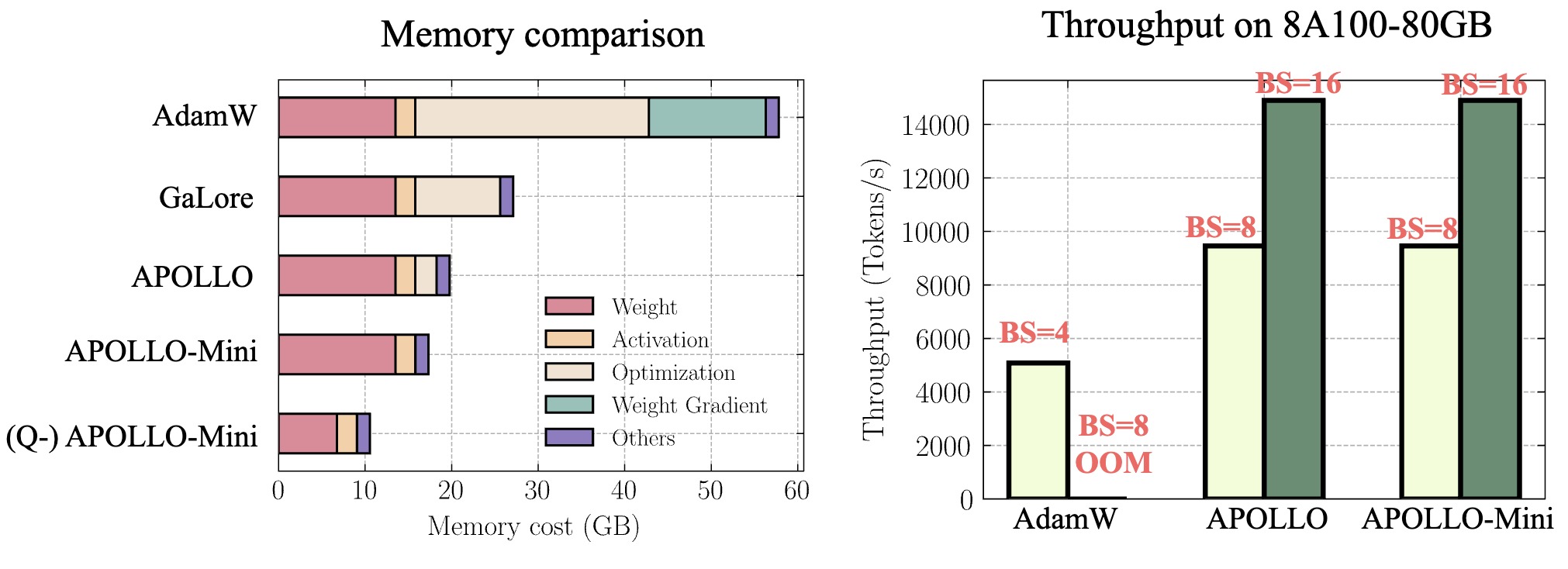
Figure 2: System Benefits of APOLLO for Pre-training LLaMA 7B. (left): Memory breakdown comparison for a single batch size; (right): End-to-end training throughput on 8 A100-80GB GPUs
You can install the APOLLO optimizer directly from pip:
pip install apollo-torchTo install APOLLO from the source code:
git clone https://github.com/zhuhanqing/APOLLO.git
cd APOLLO
pip install -e .pip install -r exp_requirements.txtfrom apollo_torch import APOLLOAdamW
# define param groups as lowrank_params and regular params
param_groups = [{'params': non_lowrank_params},
{'params':
lowrank_params,
'rank': 1,
'proj': 'random',
'scale_type': 'tensor',
'scale': 128,
'update_proj_gap': 200,
'proj_type': 'std'}]
optimizer = APOLLO(param_groups, lr=0.01)
For APOLLO and APOLLO-Mini, we have the following arguments
- Specifies the rank of the auxiliary sub-space used for gradient scaling.
- Default value:
256for APOLLO works well for 1B and 7B model.1for APOLLO-Mini.
- Determines how the scaling factors are applied:
channel: Applies gradient scaling at the channel level (APOLLO)tensor: Applies gradient scaling at the tensor level (APOLLO-Mini).
The scale parameter plays a crucial role in heuristically adjusting gradient updates to compensate for scaling factor approximation errors arising from the use of a lower rank. Proper tuning of this parameter can significantly improve performance:
1: Default value for APOLLO (validated on A100 GPUs).128: Default value for APOLLO-Mini. For larger models, experimenting with higher values is recommended.
To stabilize training, we adopt the Norm-Growth Limiter (NL) from Fira, which has shown to be slightly more effective than traditional gradient clipping.
There are two ways to apply the Norm-Growth Limiter based on when it's used relative to the heuristical (scale):
- After Scaling: NL is applied after the gradient is multiplied by the
scale.- Recommended for when training involves fewer warmup steps, e.g., LLaMA 60M and 130M with APOLLO-Mini.
- Enable this by setting
--scale_front.
- Before Scaling: NL is applied before the gradient is scaled.
- With sufficient warmup steps, both methods yield similar performance for large models.
We provide the command in scripts/benchmark_c4 for pretraining LLaMA model with sizes from 60M to 7B on C4 dataset.
# num_rank: 1 for APOLLO-Mini, 1/4 of the original dim for APOLLO (same as Galore)
# scale_type: channel or tensor
# projection type: random (option: svd)
# scale: related with rank, larger rank generally works well with smaller scale, we use 128 for rank=1
Compared to academic settings, the industry trains large language models (LLMs) with significantly longer context windows (1k-8k tokens) and on hundreds of billions of tokens.
Accordingly, we further validate the effectiveness of the APOLLO series by pre-training a LLaMA-350M on a 1024-token context window—four times larger than the original GaLore usage. To establish a robust baseline, we vary AdamW’s learning rate across [1e-3, 2.5e-3, 5e-3, 7.5e-3, 1e-2]. We also “lazily” tune the scale factor of the APOLLO series by testing APOLLO in [√1, √2, √3] and APOLLO-Mini in [√128, √256, √384], while keeping the learning rate fixed at 1e-2.
Both APOLLO and APOLLO-Mini demonstrate superior performance compared to AdamW, while drastically reducing optimizer memory usage—by as much as 1/8 or even 1/1024 of AdamW’s requirements. Moreover, these methods tend to exhibit even stronger performance in later stages, when more training tokens are involved. This makes them a highly promising option for partial LLM pre-training scenarios involving long context windows and trillions of training tokens.
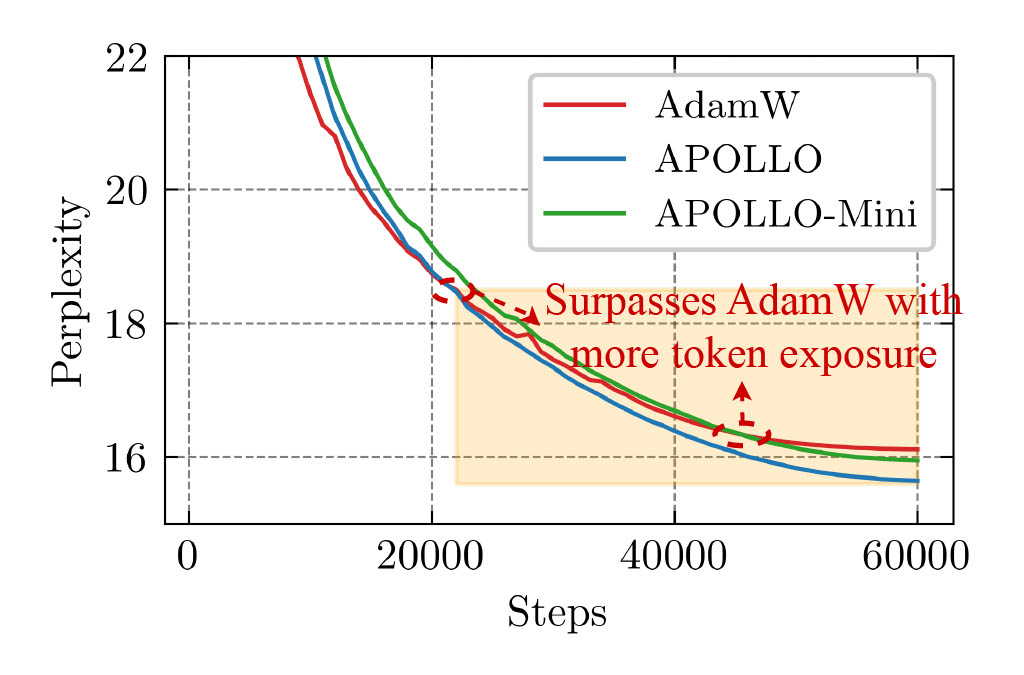
Figure 3: Perplexity curves of the LLaMA-350M model trained in a long-context window setting.
The command of training LLaMA-7B model on single GPU as provided within scripts/single_gpu. With 1 batch size, the following scripts can pre-train a LLaMA-7B model within 11GB memory (tested on a single A100 GPU)
Large language models (LLMs) demonstrate remarkable capabilities but are notoriously memory-intensive during training, particularly with the popular Adam optimizer. This memory burden often necessitates using more GPUs, smaller batch sizes, or high-end hardware, thereby limiting scalability and training efficiency. To address this, various memory-efficient optimizers have been proposed to reduce optimizer memory usage. However, they face key challenges: (i) reliance on costly SVD operations (e.g., GaLore, Fira); (ii) significant performance trade-offs compared to AdamW (e.g., Flora); and (iii) still substantial memory overhead of optimization states in order to maintain competitive performance (e.g., 1/4 rank in Galore, and full-rank first momentum in Adam-mini).
In this work, we investigate the redundancy in Adam's learning rate adaption rule and identify that it can be coarsened as a structured learning rate update (channel-wise or tensor-wise). Based on this insight, we propose a novel approach, Approximated Gradient Scaling for Memory Efficient LLM Optimization (APOLLO), which approximate the channel-wise learning rate scaling with an auxiliary low-rank optimizer state based on pure random projection. The structured learning rate update rule makes APOLLO highly tolerant to further memory reduction with lower rank, halving the rank while delivering similar pre-training performance. We further propose an extreme memory-efficient version, APOLLO-mini, which utilizes tensor-wise scaling with only a rank-1 auxiliary sub-space, achieving SGD-level memory cost but superior pre-training performance than Adam(W).
We conduct extensive experiments across different tasks and model architectures, showing that APOLLO series performs generally on-par with, or even better than Adam(W). Meanwhile, APOLLO achieves even greater memory savings than Galore, by almost eliminating the optimization states in AdamW. These savings translate into significant system benefits:
- Enhanced Throughput: APOLLO and APOLLO-mini achieve up to 3x throughput on a 4xA100-80GB setup compared to Adam by fully utilizing memory to support 4x larger batch sizes.
- Improved Model Scalability: APOLLO-mini for the first time enables pre-training LLaMA-13B model with naive DDP on A100-80G without requiring other system-level optimizations
- Low-End GPU Pre-training: Combined with quantization, the APOLLO series for the first time enables the training of LLaMA-7B from scratch using less than 12 GB of memory.
- Support APOLLO with FSDP.
For questions or collaboration inquiries, feel free to reach out our core contributors:
- 📧 Email: [email protected]
- 📧 Email: [email protected]
If you find APOLLO useful in your work, please consider citing our paper:
@misc{zhu2024apollosgdlikememoryadamwlevel,
title={APOLLO: SGD-like Memory, AdamW-level Performance},
author={Hanqing Zhu and Zhenyu Zhang and Wenyan Cong and Xi Liu and Sem Park and Vikas Chandra and Bo Long and David Z. Pan and Zhangyang Wang and Jinwon Lee},
year={2024},
eprint={2412.05270},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2412.05270},
}The majority of APOLLO is licensed under CC-BY-NC, however portions of the project are available under separate license terms: GaLore is licensed under the Apache 2.0 license.